
Load Balancing & Horizontal Scaling Trong Production: Từ Một Server Đến Scale Không Giới Hạn

#Hướng dẫn toàn diện về load balancing algorithms, horizontal scaling patterns, auto-scaling strategies và kiến trúc high-availability
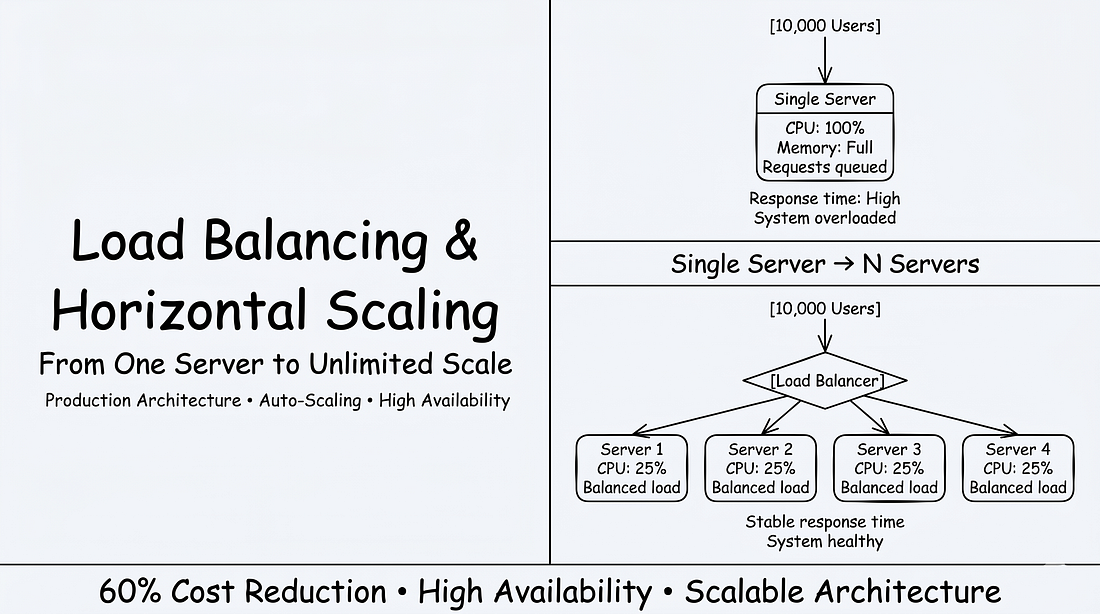
#Giới Thiệu
Một server đã crash tại 10.000 concurrent users.
Một server xử lý tất cả traffic.
CPU ở 100%.
Bộ nhớ đầy.
Response time leo lên 30 giây.
Sau đó là sụp đổ hoàn toàn.
Vấn đề không phải code. Code hoàn toàn ổn.
Vấn đề là kiến trúc — cố gắng xử lý tăng trưởng không giới hạn với tài nguyên có hạn.
- Sau đó, load balancing và horizontal scaling xuất hiện.
- Cùng 10.000 users đó, phân phối qua 4 servers.
- CPU ở 25% mỗi server.
- Response time ở 200ms.
- Zero crashes.
Và phần đáng ngạc nhiên: Rẻ hơn 60% so với một server mạnh duy nhất.
Đây là hướng dẫn toàn diện về load balancing và horizontal scaling trong production — không phải lý thuyết, mà là các patterns thực tế giúp hệ thống xử lý 10.000 users hôm nay và 100.000 users ngày mai mà không cần viết lại code.
Bạn sẽ học:
- Tại sao single servers thất bại và load balancing giải quyết nó thế nào
- Load balancing algorithms (khi nào dùng cái nào)
- Health checks và automatic failover
- Horizontal vs vertical scaling (so sánh chi phí)
- Stateless architecture requirements
- Auto-scaling strategies
- Ví dụ cấu hình production
Bắt đầu thôi.
#Phần 1: Vấn Đề Single Server
#Khi Một Trở Thành Không
Hầu hết ứng dụng bắt đầu trên một server duy nhất.
Nó đơn giản:
All Users → One Server → DatabaseĐiều này hoạt động hoàn hảo cho đến một ngày nó không còn hoạt động.
Kịch bản thực tế:
- Ra mắt sản phẩm.
- Chiến dịch marketing.
- Dự kiến 500 users mỗi phút.
- Server đã test với 1.000 concurrent users.
Timeline ra mắt:
- 9:00 AM: Announcement đi live
- 9:05 AM: 2.000 users đến (4x dự kiến)
- 9:06 AM: Server CPU ở 80%
- 9:07 AM: Response time chạm 5 giây
- 9:08 AM: 5.000 users (10x dự kiến)
- 9:09 AM: Server CPU 100%
- 9:10 AM: Server ngừng phản hồi
- 9:11 AM: Sụp đổ hoàn toàn
Kết quả:
- Ra mắt thất bại.
- Mất users.
- Trending trên mạng xã hội vì lý do sai.
#Tại Sao Single Servers Thất Bại
Vấn đề 1: Capacity cố định
Server có giới hạn vật lý:
- CPU cores: Không thể thêm kỳ diệu
- RAM: Cố định tại thời điểm provision
- Network bandwidth: Giới hạn bởi hardware
- Disk I/O: Bị ràng buộc bởi hardware
Traffic vượt quá giới hạn? Server sụp đổ.
Vấn đề 2: Single point of failure
Server crash → 100% users bị ảnh hưởng.
- Không có dự phòng.
- Không có backup.
- Một lỗi = toàn bộ ngừng hoạt động.
Vấn đề 3: Không thể scale trong khủng hoảng
- Traffic spike đang xảy ra?
- Không thể thêm capacity giữa khủng hoảng.
- Provision server lớn hơn mất 15–30 phút.
- Lúc đó, users đã bỏ đi.
Vấn đề 4: Scaling đắt đỏ
Cần thêm capacity?
Lựa chọn:
- Nâng cấp lên server lớn hơn (cần downtime)
- Migrate lên instance lớn hơn (phức tạp, rủi ro)
- Chấp nhận rằng tăng trưởng bị chặn
Tất cả đều đắt. Tất cả đều chậm. Tất cả đều rủi ro.
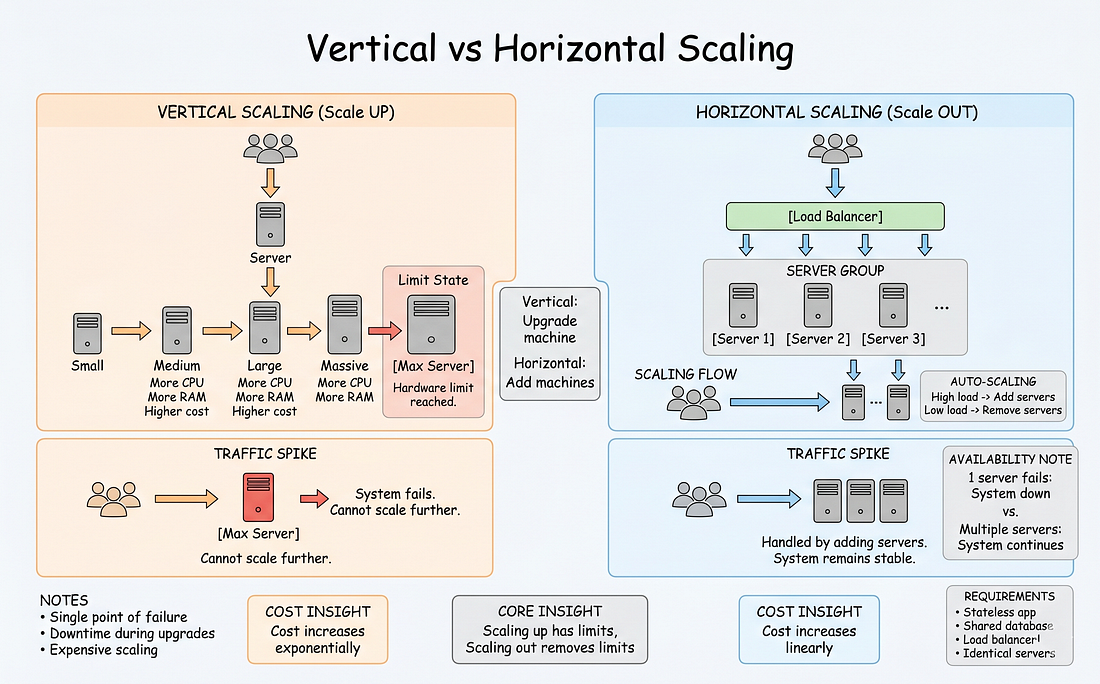
Chi phí của vertical scaling:
- Tháng 1: 4 cores, 16GB RAM → $200/tháng
- Tháng 3: 8 cores, 32GB RAM → $400/tháng
- Tháng 6: 16 cores, 64GB RAM → $800/tháng
- Tháng 9: 32 cores, 128GB RAM → $2.000/tháng
Chi phí tăng theo cấp số nhân.
Và cuối cùng, bạn chạm giới hạn vật lý — không thể mua server 128-core.
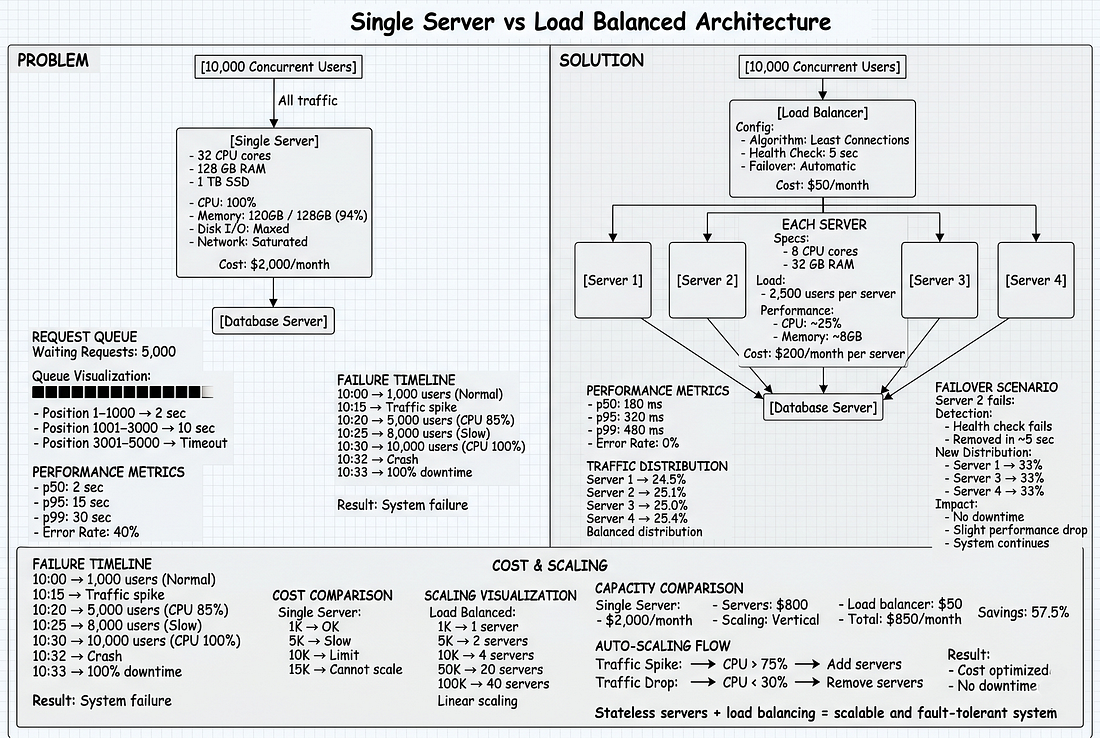
#Phần 2: Load Balancing — Giải Pháp
#Load Balancer Là Gì?
Hãy nghĩ về load balancer như người xếp chỗ trong nhà hàng.
Không có người xếp chỗ:
- Khách tự ý chọn bàn
- Vài bàn quá tải, bàn khác trống
- Hỗn loạn
Có người xếp chỗ:
- Phân phối khách đều
- Tất cả bàn được phục vụ công bằng
- Vận hành trơn tru
Load balancer là người xếp chỗ cho servers của bạn.
Nó nằm giữa users và application servers, phân phối traffic đều đặn.
Kiến trúc cơ bản:
Users
↓
Load Balancer
├→ Server 1
├→ Server 2
├→ Server 3
└→ Server 4#Cách Nó Hoạt Động
User gửi request → Load balancer nhận → Chọn server → Chuyển tiếp request → Server xử lý → Load balancer trả response về cho user.
User không bao giờ biết server nào đã xử lý request của họ.
Họ chỉ biết họ nhận được response nhanh.
Code không thay đổi:
# Trước đây (single server)
@app.get("/api/users")
def get_users():
return db.query("SELECT * FROM users")
# Sau load balancing (giống hệt!)
@app.get("/api/users")
def get_users():
return db.query("SELECT * FROM users")Không thay đổi code. Chỉ thay đổi infrastructure.
#Lợi Ích
1. Phân phối tải
- 10.000 users qua 4 servers = 2.500 mỗi server
- CPU thoải mái ở 25% thay vì 100%
- Response time nhanh được duy trì
2. High availability
- Server 1 crash?
- Traffic chuyển sang 2, 3, 4
- 75% capacity còn lại thay vì 0%
- Users thấy chậm nhẹ, không phải sập hoàn toàn
3. Zero-downtime deploys
- Deploy lên Server 1, đưa nó ra khỏi vòng quay
- Deploy lên Server 2, đưa nó ra
- Tiếp tục cho tất cả servers
- Users không bao giờ để ý
4. Horizontal scaling
- Nhiều traffic? → Thêm servers
- Ít traffic? → Bớt servers
- Scale khớp với nhu cầu
#Phần 3: Load Balancing Algorithms
Load balancer không thông minh.
Chúng tuân theo algorithms.
Chọn sai algorithm? Hệ thống "cân bằng" của bạn trở nên mất cân bằng.
#Thuật Toán 1: Round Robin
Cách hoạt động: Lần lượt như chia bài.
Request 1 → Server A
Request 2 → Server B
Request 3 → Server C
Request 4 → Server A (lặp lại)Ưu điểm: Đơn giản, có thể dự đoán, phân phối công bằng.
Nhược điểm: Bỏ qua capacity server, bỏ qua tải hiện tại, coi tất cả request như nhau.
Khi nào dùng: Tất cả servers giống hệt nhau, tất cả requests mất thời gian tương tự.
Cấu hình Nginx:
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}#Thuật Toán 2: Weighted Round Robin
Vấn đề với round robin cơ bản:
- Server A: 16 cores, 64GB RAM (mạnh)
- Server B: 4 cores, 16GB RAM (yếu)
- Server C: 8 cores, 32GB RAM (trung bình)
Round robin gửi 33% cho mỗi server.
Kết quả:
- Server A: Dưới tải
- Server B: Quá tải
- Mất cân bằng
Giải pháp: Weights
Gán weights dựa trên capacity:
upstream backend {
server backend1.example.com weight=4;
server backend2.example.com weight=1;
server backend3.example.com weight=2;
}Phân phối:
- Server A: 57% (4/7)
- Server B: 14% (1/7)
- Server C: 29% (2/7)
Utilization khớp với capacity.
Khi nào dùng: Hardware hỗn hợp, kích thước servers khác nhau.
#Thuật Toán 3: Least Connections
Cách hoạt động: Gửi request đến server có ít kết nối hoạt động nhất.
Trạng thái hiện tại:
- Server A: 50 connections
- Server B: 30 connections
- Server C: 45 connections
Request mới → Server B (ít nhất: 30)Tại sao quan trọng:
Không phải request nào cũng mất thời gian như nhau:
- Query đơn giản: 50ms
- Báo cáo phức tạp: 30 giây
Least connections tính đến điều này. Các request chạy lâu chiếm connections. Least connections tránh làm quá tải server với các request dài.
Cấu hình:
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}Khi nào dùng: Thời gian request thay đổi, có request chạy lâu, WebSocket connections, streaming responses.
#Thuật Toán 4: IP Hash (Sticky Sessions)
Cách hoạt động: Dùng IP client để xác định server:
server_index = hash(client_ip) % num_serversCùng user luôn vào cùng server.
Tại sao? Session data lưu trên server cụ thể:
- Giỏ hàng
- Trạng thái đăng nhập
- Preferences
Ví dụ:
- User 192.168.1.100 → Luôn Server B
- User 10.0.0.50 → Luôn Server A
Cấu hình:
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}Vấn đề:
- Thêm hoặc xóa servers thay đổi hash
- Users đột nhiên sang server khác
- Sessions bị mất
Giải pháp tốt hơn: Lưu sessions trong Redis (đề cập sau).
Khi nào dùng: Ứng dụng legacy không thể refactor session storage.
#Thuật Toán 5: Least Response Time
Cách hoạt động: Theo dõi thời gian response mỗi server. Gửi đến server nhanh nhất.
Hiệu suất server (100 request gần nhất):
- Server A: Trung bình 50ms
- Server B: Trung bình 150ms
- Server C: Trung bình 90ms
Request tiếp theo → Server A (nhanh nhất)Tại sao đây là tốt nhất:
Thích ứng với thực tế:
- Hiệu suất server thay đổi
- Điều kiện mạng thay đổi
- Tải không phải lúc nào cũng dự đoán được
Least response time tự động điều chỉnh dựa trên hiệu suất thực tế.
Cấu hình (AWS ALB):
{
"RoutingAlgorithm": "least_outstanding_requests",
"TargetGroup": "backend-servers"
}Khi nào dùng: Hệ thống production nơi hiệu suất quan trọng. Đáng giá độ phức tạp thêm.
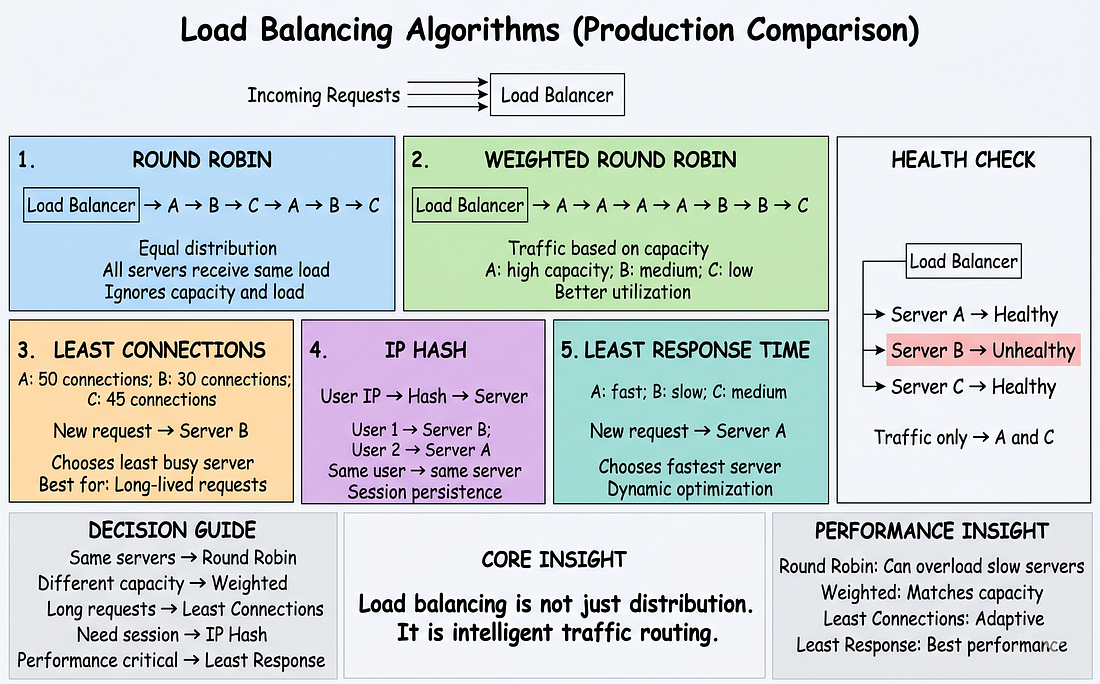
#Phần 4: Health Checks & Failover
Load balancing chỉ hoạt động nếu server không khỏe mạnh bị loại khỏi vòng quay. Health checks ra đời.
#Health Checks Hoạt Động Thế Nào
Load balancer ping mỗi server mỗi N giây:
Load Balancer: GET http://server1:8000/health
Server 1: 200 OK
Load Balancer: GET http://server2:8000/health
Server 2: <timeout - không phản hồi>
Load Balancer: Đánh dấu Server 2 unhealthy, loại khỏi vòng quay#Triển Khai Health Checks
Health check đơn giản:
@app.get("/health")
def health_check():
return {"status": "healthy"}Health check tốt hơn:
@app.get("/health")
def health_check():
try:
db.execute("SELECT 1")
except Exception:
return Response(status_code=503)
try:
redis.ping()
except Exception:
return Response(status_code=503)
if not can_process_requests():
return Response(status_code=503)
return {
"status": "healthy",
"timestamp": datetime.now().isoformat(),
"version": app_version
}Trả về:
200 OK→ Server khỏe mạnh503 Service Unavailable→ Server không khỏe
#Automatic Failover
Kịch bản: Server crash
Timeline:
10:30:00 - Server 2 chạy bình thường
10:30:15 - Server 2 crash
10:30:20 - Health check thất bại (không phản hồi)
10:30:25 - Health check thứ hai thất bại
10:30:30 - Health check thứ ba thất bại (đánh dấu unhealthy)
10:30:31 - Traffic phân phối lại sang Servers 1, 3, 4
10:30:32 - Users trải nghiệm zero downtimeCấu hình:
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
server backend4.example.com;
check interval=5000 rise=2 fall=3 timeout=3000;
}Tham số:
interval=5000: Kiểm tra mỗi 5 giâyrise=2: 2 lần thành công = đánh dấu healthyfall=3: 3 lần thất bại = đánh dấu unhealthytimeout=3000: Timeout 3 giây
#Graceful Shutdown
Khi deploy code mới:
Cách sai:
kill -9 server_processCách đúng:
import signal
import time
def graceful_shutdown(signum, frame):
print("Shutdown signal received")
server.stop_accepting()
timeout = 30
while server.has_active_requests() and timeout > 0:
time.sleep(1)
timeout -= 1
server.shutdown()
sys.exit(0)
signal.signal(signal.SIGTERM, graceful_shutdown)Luồng:
- Nhận tín hiệu shutdown
- Ngừng nhận request mới
- Hoàn thành xử lý các request đang hoạt động
- Shutdown sạch sẽ
Zero lost requests.
#Phần 5: Horizontal vs Vertical Scaling
Hai cách thêm capacity: server to hơn hoặc nhiều server hơn.
#Vertical Scaling (Scale UP)
Mua server to hơn.
Đường tăng trưởng:
- Tháng 1: 4 cores, 16GB → $200/tháng
- Tháng 3: 8 cores, 32GB → $400/tháng
- Tháng 6: 16 cores, 64GB → $800/tháng
- Tháng 9: 32 cores, 128GB → $2.000/tháng
Vấn đề:
Chi phí tăng theo cấp số nhân
- Server to hơn không có giá tuyến tính
- Server 32-core đắt gấp 10 lần server 4-core
Giới hạn vật lý
- Không thể mua server 1.000-core
- Hardware có giới hạn
Single point of failure
- Một server = một điểm lỗi
- Server chết = 100% downtime
Downtime cho nâng cấp
- Phải dừng server
- Migrate lên hardware mới
- 15–60 phút downtime
#Horizontal Scaling (Scale OUT)
Thêm nhiều server hơn.
Đường tăng trưởng:
- Tháng 1: 1 server (4 cores) → $200/tháng
- Tháng 3: 2 servers → $400/tháng
- Tháng 6: 4 servers → $800/tháng
- Tháng 9: 8 servers → $1.600/tháng
Lợi ích:
Chi phí tuyến tính
- Gấp đôi capacity = gấp đôi chi phí
- Scaling có thể dự đoán
Capacity không giới hạn
- Thêm bao nhiêu server cũng được
- Không có giới hạn vật lý
High availability
- Nhiều servers = dự phòng
- Một server chết = các server khác tiếp tục
Zero-downtime deploys
- Rolling updates
- Deploy từng server một
#So Sánh Chi Phí Thực Tế
Tại 40.000 concurrent users:
| Tiêu chí | Vertical | Horizontal |
|---|---|---|
| Cấu hình | 1 server: 64 cores, 256GB RAM | 20 servers: 4 cores, 16GB mỗi cái |
| Chi phí | $5.000/tháng | $3.000/tháng |
| Availability | 99% (single point of failure) | 99.99% (dự phòng) |
Horizontal = rẻ hơn 40% + availability tốt hơn.
#Phần 6: Stateless Architecture
Để scale theo chiều ngang, ứng dụng của bạn phải stateless.
#Stateful vs Stateless
Stateful (phá vỡ horizontal scaling):
user_sessions = {} # Lưu trong bộ nhớ server!
@app.post("/login")
def login(user_id: int):
user_sessions[user_id] = {"logged_in": True, "cart": []}
@app.get("/cart")
def get_cart(user_id: int):
return user_sessions[user_id]["cart"]Vấn đề:
- User đăng nhập → Server 1 (session lưu ở đây)
- Request tiếp theo → Load balancer gửi đến Server 2
- Server 2 không có session
- User bị logout! (X)
Stateless (horizontal scaling hoạt động):
@app.post("/login")
def login(user_id: int):
session_data = {"logged_in": True, "cart": []}
redis.set(f"session:{user_id}", json.dumps(session_data), ex=3600)
@app.get("/cart")
def get_cart(user_id: int):
session = json.loads(redis.get(f"session:{user_id}"))
return session["cart"]Bất kỳ server nào cũng có thể xử lý bất kỳ request nào.
Session trong Redis, tất cả servers đều có thể truy cập.
#Yêu Cầu Stateless
1. Không lưu session local
- In-memory sessions ✕
- Local files cho sessions ✕
- Redis cho sessions ✔
- Database cho sessions ✔
2. Không lưu file local
- Lưu uploads vào thư mục
/uploads✕ - Generate PDFs trong
/tmp✕ - Upload lên S3 ✔
- Generate PDF, upload lên S3, trả về URL ✔
3. Shared database
Tất cả servers kết nối cùng database:
DATABASE_URL = "postgresql://db.example.com:5432/app"4. Shared cache
Tất cả servers dùng cùng Redis:
REDIS_URL = "redis://cache.example.com:6379"#Migration Sang Stateless
Trước đây (stateful):
sessions = {}
def store_session(user_id, data):
sessions[user_id] = data
def get_session(user_id):
return sessions.get(user_id)Sau đó (stateless):
import redis
redis_client = redis.Redis(host='cache.example.com')
def store_session(user_id, data):
redis_client.setex(
f"session:{user_id}",
3600,
json.dumps(data)
)
def get_session(user_id):
data = redis_client.get(f"session:{user_id}")
return json.loads(data) if data else None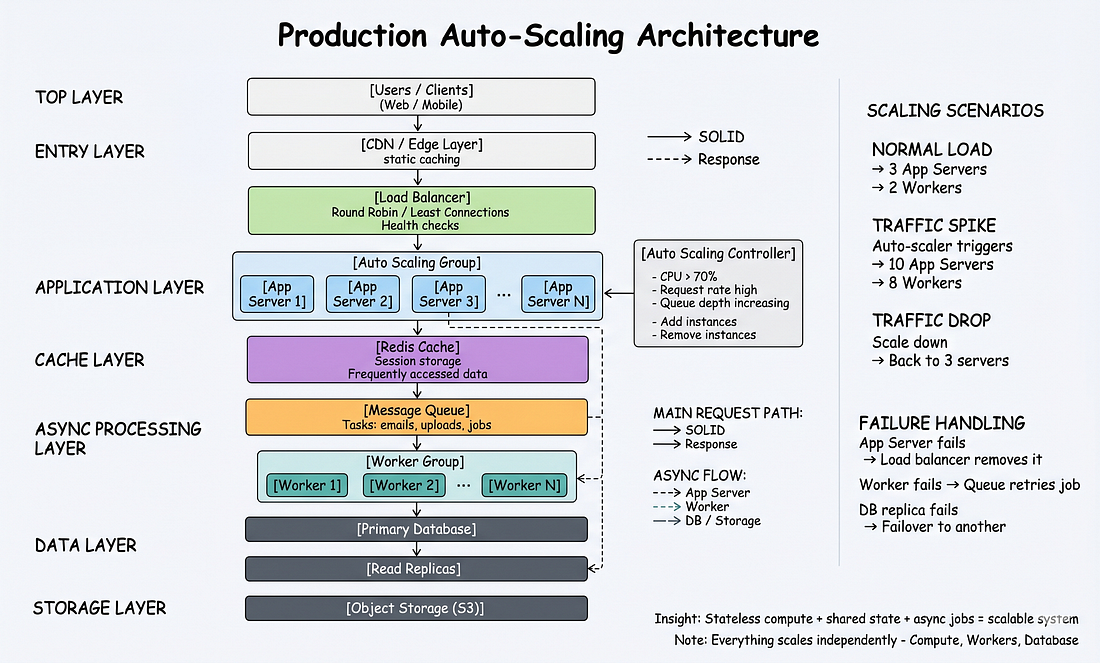
#Phần 7: Auto-Scaling
Auto-scaling tự động thêm/xóa servers dựa trên nhu cầu.
#Khi Nào Scale
Kích hoạt Scale UP:
- CPU > 70% trong 5 phút
- Memory > 80% trong 5 phút
- Request queue > 100
Kích hoạt Scale DOWN:
- CPU < 30% trong 10 phút
- Memory < 40% trong 10 phút
- Request queue < 10
#Cấu Hình Auto-Scaling
AWS Auto Scaling:
{
"AutoScalingGroupName": "app-servers",
"MinSize": 2,
"MaxSize": 20,
"DesiredCapacity": 4,
"TargetTrackingConfiguration": {
"TargetValue": 70.0,
"PredefinedMetricSpecification": {
"PredefinedMetricType": "ASGAverageCPUUtilization"
}
}
}Tham số:
- Min: 2 servers (luôn chạy)
- Max: 20 servers (giới hạn chi phí)
- Target: 70% CPU trung bình
- Current: 4 servers
Cách hoạt động:
Traffic bình thường (4 servers, 50% CPU):
→ Không cần scaling
Traffic spike (4 servers, 85% CPU):
→ Vượt target (70%)
→ Launch 2 servers mới
→ 6 servers, 57% CPU
→ Ổn định
Traffic giảm (6 servers, 25% CPU):
→ Dưới target (70%)
→ Terminate 2 servers
→ 4 servers, 38% CPU
→ Ổn định#Tác Động Chi Phí
Không auto-scaling:
Luôn chạy 10 servers cho peak capacity.
- Giờ cao điểm (4 giờ/ngày): Cần 10 servers
- Giờ bình thường (20 giờ/ngày): Cần 4 servers
- Chi phí: 10 servers × 24 giờ = 240 server-giờ/ngày
- Chi phí tháng: $3.000
Có auto-scaling:
Scale theo nhu cầu.
- Giờ cao điểm: 10 servers × 4 giờ = 40 server-giờ
- Giờ bình thường: 4 servers × 20 giờ = 80 server-giờ
- Tổng: 120 server-giờ/ngày
- Chi phí tháng: $1.500
Tiết kiệm 50% chi phí.
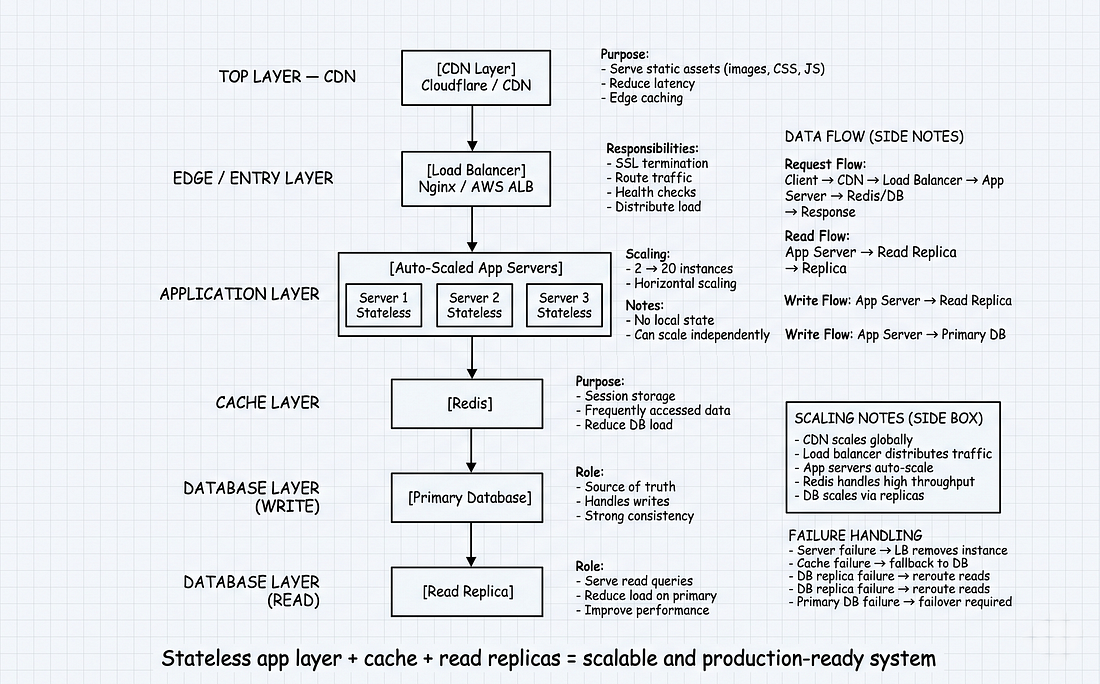
#Phần 8: Kiến Trúc Production
Thiết lập production hoàn chỉnh:
┌──────────────────────┐
│ CDN (CloudFlare) │ Static assets
└──────────────────────┘
↓
┌──────────────────────┐
│ Load Balancer (LB) │ SSL termination
│ Nginx / AWS ALB │ Health checks
└──────────────────────┘
↓ ↓ ↓
┌────────┐┌────────┐┌────────┐
│Server 1││Server 2││Server 3│ Auto-scaled
│ ││ ││ │ 2-20 instances
└────────┘└────────┘└────────┘
↓
┌──────────┐
│ Redis │ Session store
└──────────┘ Cache layer
↓
┌──────────┐
│ Database │ Primary
│(Primary) │
└──────────┘
↓
┌──────────┐
│ Database │ Read replica
│(Replica) │ (Week 6 topic)
└──────────┘#Cấu Hình Nginx Hoàn Chỉnh
upstream app_servers {
least_conn;
server 10.0.1.10:8000 weight=1;
server 10.0.1.11:8000 weight=1;
server 10.0.1.12:8000 weight=1;
server 10.0.1.13:8000 weight=1;
check interval=5s fails=3 passes=2 timeout=3s;
keepalive 32;
}
server {
listen 80;
server_name api.example.com;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
server_name api.example.com;
ssl_certificate /etc/ssl/certs/api.crt;
ssl_certificate_key /etc/ssl/private/api.key;
location / {
proxy_pass http://app_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 5s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering on;
proxy_buffer_size 4k;
proxy_buffers 8 4k;
}
location /health {
access_log off;
return 200 "healthy\n";
}
}#Monitoring Dashboard
from prometheus_client import Counter, Histogram, Gauge
request_count = Counter('http_requests_total', 'Total requests',
['method', 'endpoint', 'status'])
request_duration = Histogram('http_request_duration_seconds',
'Request duration')
active_servers = Gauge('active_servers', 'Active servers')
cpu_usage = Gauge('cpu_usage_percent', 'CPU usage', ['server'])
memory_usage = Gauge('memory_usage_percent', 'Memory usage', ['server'])
requests_per_server = Counter('requests_per_server', 'Requests', ['server'])
failed_health_checks = Counter('failed_health_checks',
'Failed checks', ['server'])Dashboard hiển thị:
- Request rate mỗi server
- Response time mỗi server
- CPU/memory mỗi server
- Health check status
- Auto-scaling events
#Phần 9: Những Sai Lầm Thường Gặp
Sai lầm 1: Không có health checks
- Servers hỏng.
- Không có health checks, server chết vẫn nhận traffic.
- Luôn implement comprehensive health checks.
Sai lầm 2: Dùng round robin với hardware hỗn hợp
- Server A: 16 cores
- Server B: 4 cores
- Round robin gửi traffic bằng nhau.
- Server B quá tải.
- Dùng weighted round robin hoặc least response time.
Sai lầm 3: Session affinity khi không cần
- IP hash tạo phân phối không đều.
- Tránh trừ khi thực sự cần.
- Tốt hơn: Lưu sessions trong Redis.
- Bất kỳ server nào cũng xử lý được request nào.
Sai lầm 4: Không graceful shutdown
- Kill server ngay lập tức làm mất các request đang xử lý.
- Implement graceful shutdown.
Sai lầm 5: Lưu file local
- Lưu uploads trên ổ đĩa local gây hỏng với nhiều servers.
- Luôn dùng S3 hoặc cloud storage.
#Tổng Kết
#Từ Một Đến Nhiều
Trước đây (Single server):
- Capacity cố định.
- Single point of failure.
- Đắt để scale.
Sau đó (Load balancing + Horizontal scaling):
- Traffic được phân phối.
- High availability.
- Horizontal scaling.
Tác động thực tế:
- Capacity: 1.000 → 10.000+ users (10x)
- Chi phí: $2.000 → $800/tháng (tiết kiệm 60%)
- Availability: 99% → 99.99% (tốt hơn 100x)
- Deploys: 15 phút downtime → 0 phút downtime
Hiệu suất tốt hơn. Chi phí thấp hơn. Độ tin cậy cao hơn.
#Bài Học Chính
- Load balancing cho phép scaling → Thêm servers, không phải server to hơn
- Chọn algorithm cẩn thận → Least connections hoặc least response time cho hầu hết trường hợp
- Health checks là bắt buộc → Automatic failover ngăn chặn downtime
- Horizontal > Vertical → Rẻ hơn, đáng tin cậy hơn, scale không giới hạn
- Stateless architecture là yêu cầu → Sessions trong Redis, files trong S3
- Auto-scaling tiết kiệm tiền → Trả cho những gì bạn dùng