
Thiết Kế API & Database: Từ Code Chạy Được Đến Hệ Thống Mở Rộng

#Tuần 1 của Series 90 Ngày về Thiết Kế Hệ Thống
Dành cho các kỹ sư muốn chuyển từ code chạy được sang hệ thống sống sót qua môi trường production.
#Giới Thiệu: Khoảng Cách Giữa Development và Production
Bạn đã viết code.
Nó chạy trên máy tính của bạn.
Test pass.
Bạn deploy.
Sau đó production xảy ra.
Đột nhiên:
- API của bạn trả về 50MB dữ liệu và timeout
- Câu truy vấn database mất 3 giây thay vì 3 mili giây
- Server crash khi 100 người dùng truy cập cùng lúc
- Tech lead của bạn hỏi: "Em có thêm index không?"
Bạn không biết là mình cần chúng.
Đây là khoảng cách giữa code chạy được và hệ thống mở rộng được. Bài viết này sẽ lấp đầy khoảng cách đó.
Trong hơn 2.500 từ tiếp theo, tôi sẽ chia sẻ những kiến thức nền tảng mà tôi ước ai đó đã dạy tôi từ ngày đầu:
- Thiết Kế REST API → Cách xây dựng API nhanh, có thể cache, và dễ bảo trì
- Chọn Database → PostgreSQL vs MongoDB (và khi nào dùng cái gì)
- Database Indexes → Nhân tố hiệu suất 100x
- API Response Patterns → Phân trang, lọc, và sắp xếp
Đây không phải là chủ đề nâng cao.
Chúng là chủ đề nền tảng giúp phân biệt kỹ sư ship tính năng với kỹ sư xây dựng hệ thống.
Bắt đầu thôi.
#Phần 1: Nguyên Tắc Thiết Kế REST API
#Nền Tảng: Thiết Kế Dựa Trên Resource
Hầu hết các developer bắt đầu xây dựng API như thế này:
POST /getUserById
POST /createNewUser
POST /updateUserEmail
POST /deleteUserAccountĐây không phải REST.
Đây là RPC (Remote Procedure Call) qua HTTP.
Vấn đề ở đây là:
- Mọi endpoint đều là một hành động tùy chỉnh
- Không có tính nhất quán
- Không có chuẩn mực
- Không thể cache
REST (Representational State Transfer) khác. Nó xoay quanh resource, không phải hành động:
GET /users/{id} # Đọc user
POST /users # Tạo user
PATCH /users/{id} # Cập nhật user
DELETE /users/{id} # Xóa userTại sao điều này quan trọng trong production:
- Có thể cache mặc định → GET request có thể được cache bởi browser, CDN, và reverse proxy
- Có thể dự đoán được → Bất kỳ developer nào cũng biết GET /users/123 làm gì
- Có thể mở rộng → Thêm load balancer rất dễ dàng với stateless resources
- Dễ debug → HTTP status code cho bạn biết chính xác chuyện gì đã xảy ra
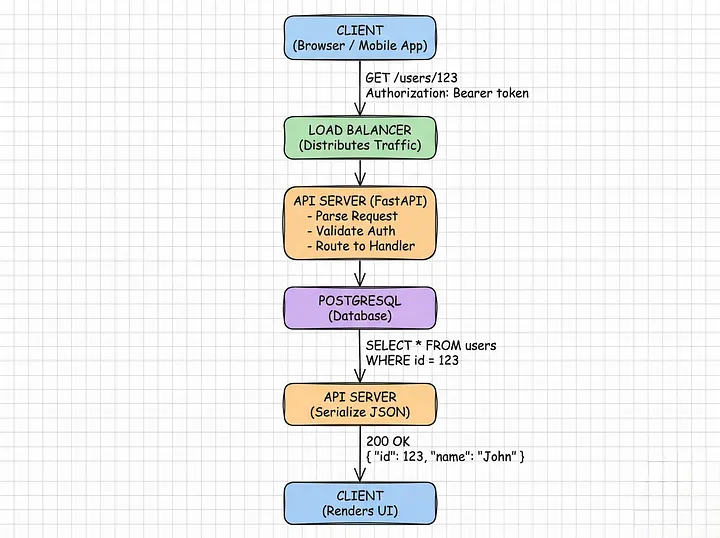
#HTTP Methods: Ngôn Ngữ của REST
Mỗi HTTP method có ngữ nghĩa cụ thể:
GET → Lấy resource
- Idempotent (gọi 10 lần = gọi 1 lần)
- Có thể cache
- Không cần body
POST → Tạo resource mới
- Không idempotent (tạo resource mới mỗi lần)
- Response: 201 Created + Location header
- Body chứa dữ liệu resource
PUT → Thay thế toàn bộ resource
- Idempotent (kết quả giống nhau mỗi lần)
- Thay thế TẤT CẢ các trường
- Dùng khi bạn muốn ghi đè
PATCH → Cập nhật một phần resource
- Cập nhật các trường cụ thể
- Linh hoạt hơn PUT
- Phổ biến nhất cho cập nhật
DELETE → Xóa resource
- Idempotent
- Response: 204 No Content
- Resource sẽ biến mất
Đây là ví dụ hoàn chỉnh với FastAPI:
from fastapi import FastAPI, HTTPException, status
from pydantic import BaseModel
from typing import Optional
app = FastAPI()
class User(BaseModel):
name: str
email: str
age: Optional[int] = None
class UserUpdate(BaseModel):
name: Optional[str] = None
email: Optional[str] = None
age: Optional[int] = None
# READ - Lấy một user
@app.get("/users/{user_id}")
def get_user(user_id: int):
user = db.get_user(user_id)
if not user:
raise HTTPException(
status_code=404,
detail=f"User {user_id} not found"
)
return user
# CREATE - Tạo user mới
@app.post("/users", status_code=status.HTTP_201_CREATED)
def create_user(user: User):
# Kiểm tra email đã tồn tại chưa
if db.email_exists(user.email):
raise HTTPException(
status_code=400,
detail="Email already registered"
)
user_id = db.create_user(user)
return {
"id": user_id,
"name": user.name,
"email": user.email,
"message": "User created successfully"
}
# UPDATE - Cập nhật một phần
@app.patch("/users/{user_id}")
def update_user(user_id: int, user: UserUpdate):
if not db.user_exists(user_id):
raise HTTPException(status_code=404, detail="User not found")
# Chỉ cập nhật các trường được cung cấp
db.update_user(user_id, user.dict(exclude_unset=True))
return {"message": "User updated successfully"}
# DELETE - Xóa user
@app.delete("/users/{user_id}", status_code=status.HTTP_204_NO_CONTENT)
def delete_user(user_id: int):
if not db.user_exists(user_id):
raise HTTPException(status_code=404, detail="User not found")
db.delete_user(user_id)
# 204 responses không có body#HTTP Status Codes: Kể Câu Chuyện
Status code không chỉ là những con số.
Chúng là một giao thức giao tiếp giữa API của bạn và client.
2xx → Nhóm thành công
- 200 OK — Request thành công
- 201 Created — Resource được tạo thành công
- 204 No Content — Thành công, nhưng không có response body
4xx → Nhóm lỗi client
- 400 Bad Request — Dữ liệu không hợp lệ từ client
- 401 Unauthorized — Yêu cầu xác thực
- 403 Forbidden — Đã xác thực nhưng không được phép
- 404 Not Found — Resource không tồn tại
- 409 Conflict — Xung đột resource (email trùng)
- 422 Unprocessable Entity — Validation thất bại
5xx → Nhóm lỗi server
- 500 Internal Server Error — Server crash
- 502 Bad Gateway — Lỗi upstream server
- 503 Service Unavailable — Server quá tải
- 504 Gateway Timeout — Upstream timeout
Ví dụ debug production:
@app.post("/checkout")
def checkout(order: Order):
try:
# Kiểm tra tồn kho
if not inventory.check_stock(order.items):
raise HTTPException(
status_code=409, # Conflict
detail="Some items are out of stock"
)
# Xử lý thanh toán
payment = payment_service.charge(order.total)
if payment.status == "failed":
raise HTTPException(
status_code=402, # Payment Required
detail="Payment failed"
)
# Tạo order
order_id = db.create_order(order)
return {"order_id": order_id, "status": "confirmed"}
except PaymentServiceTimeout:
raise HTTPException(
status_code=504, # Gateway Timeout
detail="Payment service timeout. Please try again."
)
except Exception as e:
# Log lỗi để debug
logger.error(f"Checkout failed: {e}")
raise HTTPException(
status_code=500,
detail="Internal server error"
)Khi debug trong production, status code cho bạn biết vấn đề ở đâu:
- 4xx = Client gửi dữ liệu sai
- 5xx = Server/dependencies của bạn bị lỗi
#Thiết Kế Stateless: Chìa Khóa Để Mở Rộng
Stateless có nghĩa là mỗi request chứa tất cả thông tin cần thiết để xử lý nó. Không lưu trữ session ở phía server.
Tại sao điều này quan trọng:
Với sessions (stateful):
Request 1 → Server A (lưu session)
Request 2 → Server B (không có session) → ERROR!Bạn bị mắc kẹt với sticky sessions.
Khó mở rộng.
Với tokens (stateless):
Request 1 → Server A (xác thực token)
Request 2 → Server B (xác thực token)
Request 3 → Server C (xác thực token)Bất kỳ server nào cũng có thể xử lý bất kỳ request nào.
Dễ dàng mở rộng theo chiều ngang.
Ví dụ → Xác thực JWT token:
from fastapi import Depends, HTTPException
from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials
import jwt
security = HTTPBearer()
def verify_token(credentials: HTTPAuthorizationCredentials = Depends(security)):
try:
# Giải mã JWT (không cần tra cứu database!)
payload = jwt.decode(
credentials.credentials,
SECRET_KEY,
algorithms=["HS256"]
)
return payload["user_id"]
except jwt.ExpiredSignatureError:
raise HTTPException(status_code=401, detail="Token expired")
except jwt.InvalidTokenError:
raise HTTPException(status_code=401, detail="Invalid token")
@app.get("/profile")
def get_profile(user_id: int = Depends(verify_token)):
# user_id được lấy từ token, không cần session
return db.get_user(user_id)Bài học chính:
- Thiết kế API của bạn theo hướng stateless ngay từ ngày đầu
- Bạn trong tương lai sẽ cảm ơn bạn khi cần thêm server thứ hai
#Phần 2: Chiến Lược Chọn Database
#Quyết Định Kiến Trúc Quan Trọng Nhất
Chọn giữa SQL và NoSQL không phải là cái nào "tốt hơn".
Mà là khớp model dữ liệu của bạn với model database.
Chọn sai = hàng tháng trời đau khổ.
Để tôi chỉ cho bạn.
#Khi Nào SQL (Relational Databases) Thắng
Dùng PostgreSQL/MySQL khi bạn có:
- Quan hệ rõ ràng giữa dữ liệu
- Cần ACID transactions
- Truy vấn phức tạp với JOIN
- Schema có cấu trúc, có thể dự đoán
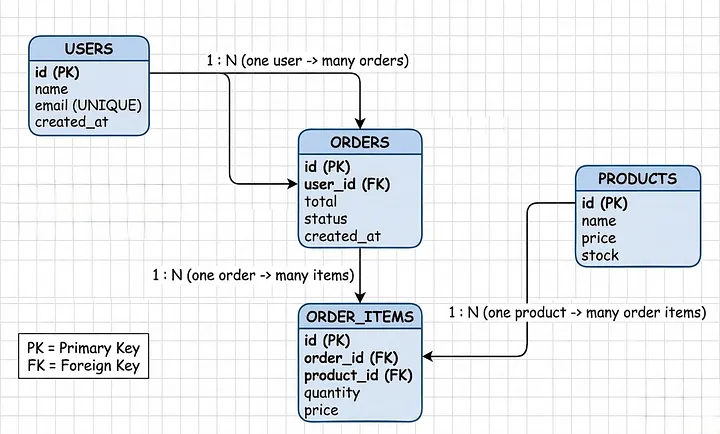
Ví dụ thực tế: Nền tảng Thương mại Điện tử
Model dữ liệu của bạn:
- Users đặt orders
- Orders chứa nhiều items
- Items tham chiếu products
- Orders có payments
Điều này về bản chất là quan hệ (relational).
Đây là lý do SQL thắng:
-- Lấy order hoàn chỉnh với tất cả chi tiết
SELECT
o.id as order_id,
o.created_at,
o.total,
u.name as customer_name,
u.email as customer_email,
p.name as product_name,
oi.quantity,
oi.price
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN order_items oi ON oi.order_id = o.id
JOIN products p ON oi.product_id = p.id
WHERE o.id = 12345;Trong một query duy nhất, bạn có:
- Chi tiết order
- Thông tin khách hàng
- Tất cả items trong order
- Chi tiết sản phẩm cho mỗi item
Thử làm điều này trong MongoDB?
Bạn sẽ cần:
- 4 query riêng biệt
- Join thủ công trong code ứng dụng
- 50+ dòng code
- Hiệu suất chậm hơn
SQL relationshiip diagram
Nhưng đây là phần QUAN TRỌNG → ACID transactions:
-- Xử lý thanh toán và tạo order (NGUYÊN TỬ)
BEGIN TRANSACTION;
-- 1. Trừ từ tài khoản user
UPDATE accounts
SET balance = balance - 99.99
WHERE user_id = 123;
-- 2. Tạo bản ghi thanh toán
INSERT INTO payments (user_id, amount, status)
VALUES (123, 99.99, 'completed');
-- 3. Tạo order
INSERT INTO orders (user_id, total, status)
VALUES (123, 99.99, 'confirmed');
-- 4. Giảm tồn kho
UPDATE products
SET stock = stock - 1
WHERE id = 456;
-- Nếu BẤT KỲ bước nào thất bại, TOÀN BỘ transaction rollback
-- User không bị tính tiền nếu order không được tạo
-- Tồn kho không giảm nếu thanh toán thất bại
COMMIT;Đây là ACID (Atomicity, Consistency, Isolation, Durability).
Nếu server crash giữa bước 2 và 3?
Database rollback lại tất cả.
Tiền của user an toàn.
Tồn kho chính xác.
Đây là lý do ngân hàng, thương mại điện tử, và fintech dùng SQL.
#Khi Nào NoSQL (Document Databases) Thắng
Dùng MongoDB/DynamoDB khi bạn có:
- Schema linh hoạt, thay đổi liên tục
- Khối lượng ghi lớn (hàng triệu sự kiện/ngày)
- Truy vấn đơn giản (key-value lookups)
- Cần mở rộng theo chiều ngang NGAY
Ví dụ thực tế: Ghi Log Hoạt Động
Bạn đang xây dựng nền tảng analytics.
Người dùng tạo ra hàng triệu sự kiện mỗi ngày.
Mỗi sự kiện có cấu trúc khác nhau:
// Sự kiện xem trang
{
"_id": "evt_123",
"event_type": "page_view",
"user_id": 456,
"page": "/products/iphone",
"timestamp": "2026-03-20T10:30:00Z",
"metadata": {
"device": "mobile",
"browser": "Chrome 120",
"screen_size": "390x844",
"referrer": "google.com"
}
}
// Sự kiện mua hàng (các trường hoàn toàn khác!)
{
"_id": "evt_124",
"event_type": "purchase",
"user_id": 456,
"order_id": "ord_789",
"amount": 999.99,
"items": [
{"product_id": 1, "name": "iPhone", "quantity": 1}
],
"timestamp": "2026-03-20T10:35:00Z",
"payment": {
"method": "stripe",
"card_type": "visa"
}
}Trong PostgreSQL, bạn sẽ cần:
- Các bảng riêng cho mỗi loại sự kiện (ác mộng bảo trì)
- HOẶC cột JSONB (hoạt động được, nhưng mất một số lợi ích của SQL)
- Schema migrations cho các loại sự kiện mới
Trong MongoDB, bạn chỉ cần insert:
- Không cần schema
- Cấu trúc linh hoạt
- Ghi nhanh
- Dễ dàng truy vấn theo event_type
// Truy vấn đơn giản
db.events.find({ user_id: 456, event_type: 'purchase' });
db.events.find({ timestamp: { $gte: '2026-03-20' } });
db.events.countDocuments({ event_type: 'page_view' });#Phương Pháp Kết Hợp (Những Gì Chúng Ta Thực Sự Dùng)
Đây là sự thật khó chịu:
Hầu hết các hệ thống production dùng CẢ HAI.
Kiến trúc nền tảng thương mại điện tử:
┌──────────────────────────────────────┐
│ POSTGRESQL │
│ (Logic Kinh Doanh Cốt Lõi) │
├──────────────────────────────────────┤
│ • users (cần ACID) │
│ • orders (quan hệ quan trọng) │
│ • payments (ACID thiết yếu) │
│ • products (dữ liệu có cấu trúc) │
│ • inventory (nhất quán quan trọng) │
└──────────────────────────────────────┘
┌──────────────────────────────────────┐
│ MONGODB │
│ (Khối Lượng Cao/Linh Hoạt) │
├──────────────────────────────────────┤
│ • activity_logs (5M sự kiện/ngày) │
│ • product_reviews (schema linh hoạt) │
│ • user_sessions (ghi nhanh) │
│ • analytics_events (không schema) │
│ • search_indexes (denormalized) │
└──────────────────────────────────────┘Ví dụ code → Dùng cả hai:
from sqlalchemy import create_engine
from pymongo import MongoClient
# PostgreSQL cho core business
pg_db = create_engine("postgresql://localhost/ecommerce")
# MongoDB cho events/logs
mongo_client = MongoClient("mongodb://localhost:27017")
mongo_db = mongo_client["analytics"]
@app.post("/checkout")
def checkout(order: Order):
# PostgreSQL: Transaction quan trọng
with pg_db.begin() as conn:
# Tạo order (cần ACID)
result = conn.execute("""
INSERT INTO orders (user_id, total, status)
VALUES (:user_id, :total, 'confirmed')
RETURNING id
""", {"user_id": order.user_id, "total": order.total})
order_id = result.fetchone()[0]
# MongoDB: Ghi log sự kiện (nhanh, không quan trọng)
mongo_db.events.insert_one({
"event_type": "checkout",
"user_id": order.user_id,
"order_id": order_id,
"timestamp": datetime.now(),
"metadata": {
"items_count": len(order.items),
"device": request.headers.get("User-Agent")
}
})
return {"order_id": order_id}Tại sao kết hợp hiệu quả:
- PostgreSQL đảm bảo tính đúng đắn cho dữ liệu quan trọng
- MongoDB xử lý khối lượng lớn mà không làm chậm PostgreSQL
- Mỗi database làm điều nó giỏi nhất
#Phần 3: Database Indexes → Nhân Tố Hiệu Suất 100x
#Vấn Đề: Sequential Scans
Bạn deploy ứng dụng.
Nó hoạt động tốt với 100 người dùng.
Sau đó bạn đạt 10.000 người dùng.
Đột nhiên, query mất 50ms giờ mất 5 giây.
Chuyện gì đã xảy ra?
Để tôi chỉ cho bạn với một tình huống thực tế:
-- Câu query có vẻ vô hại của bạn
SELECT * FROM users WHERE email = 'john@example.com';Không có index, PostgreSQL làm thế này:
Scanning 1,000,000 rows...
Row 1: alice@example.com ≠ john@example.com
Row 2: bob@example.com ≠ john@example.com
Row 3: carol@example.com ≠ john@example.com
...
Row 50,000: john@example.com ✓ FOUND!
...nhưng vẫn kiểm tra tiếp để xem có trùng không...
Row 1,000,000: zoe@example.com ≠ john@example.com
Time: 2,000ms
Rows examined: 1,000,000Đây gọi là Sequential Scan.
Nó giống như đọc cả cuốn sách để tìm một câu.
#Giải Pháp: Indexes
Index giống như trang mục lục của sách. Thay vì đọc hết mọi thứ, bạn nhảy thẳng đến những gì bạn cần.
-- Thêm một dòng
CREATE INDEX idx_users_email ON users(email);
-- Giờ chạy cùng query
SELECT * FROM users WHERE email = 'john@example.com';Với index, PostgreSQL làm thế này:
Using B-tree index idx_users_email...
1. Check root node → "john" in range [g-m]
2. Navigate to branch → found range [j-k]
3. Navigate to leaf → found exact email
4. Jump to row 50,000
Time: 5ms
Nodes examined: ~20 (not 1,000,000!)Từ 2.000ms xuống còn 5ms.
Nhanh hơn 400 lần.
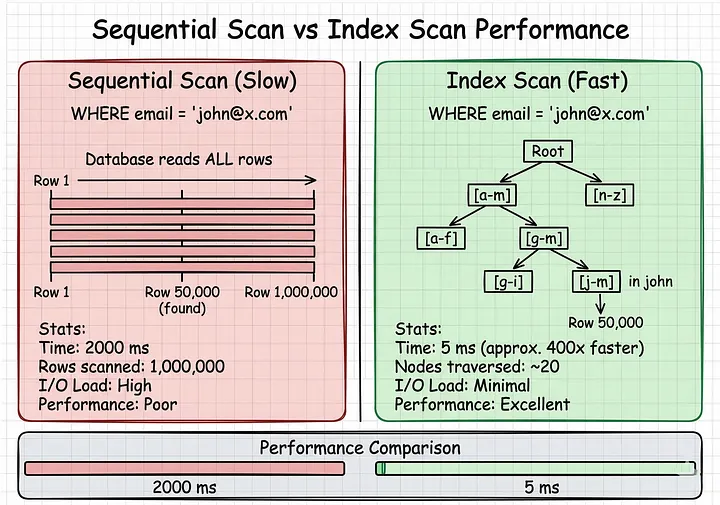
#Cách Tìm Index Bị Thiếu
Đừng đoán.
Dùng EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT * FROM users WHERE email = 'john@example.com';Không có index, bạn sẽ thấy:
Seq Scan on users (cost=0.00..25000.00 rows=1 width=100)
(actual time=500.000..2000.000 rows=1 loops=1)
Filter: (email = 'john@example.com')
Rows Removed by Filter: 999999
Planning Time: 0.500 ms
Execution Time: 2000.000 msCờ đỏ:
- "Seq Scan" → Đọc tất cả các dòng
- "Rows Removed by Filter: 999999" → Công việc lãng phí
- "Execution Time: 2000ms" → Quá chậm
Có index, bạn sẽ thấy:
Index Scan using idx_users_email on users
(cost=0.42..8.44 rows=1 width=100)
(actual time=0.050..0.055 rows=1 loops=1)
Index Cond: (email = 'john@example.com')
Planning Time: 0.100 ms
Execution Time: 0.055 msCờ xanh:
- "Index Scan" → Đang dùng index
- "Index Cond" → Điều kiện được khớp trong index
- "Execution Time: 0.055ms" → Nhanh!
#Khi Nào Thêm Index
Index các cột này:
-- Cột trong WHERE clauses
WHERE email = ?
WHERE user_id = ?
WHERE created_at > ?
-- Cột trong ORDER BY
ORDER BY created_at DESC
-- Cột trong JOIN conditions
JOIN orders ON orders.user_id = users.id
-- Foreign keys (LUÔN LUÔN)
FOREIGN KEY (user_id) REFERENCES users(id)Đừng index các cột này:
-- Cột bạn không bao giờ query
description, biography, notes
-- Cột có ít giá trị riêng biệt
gender (chỉ 3 giá trị: M/F/Other)
status (chỉ 5 giá trị: active/pending/suspended/deleted/archived)
-- Cột có tần suất ghi cao nhưng đọc hiếm
last_login_at, page_view_count#Sự Đánh Đổi Của Index
Index không miễn phí.
Chúng tốn:
- Dung lượng đĩa → Index lưu bản sao dữ liệu cột
- Tốc độ ghi → Mỗi INSERT/UPDATE phải cập nhật index
- Bộ nhớ → Index được nạp vào RAM
Ví dụ:
-- Không có index
INSERT INTO users (name, email) VALUES ('John', 'john@x.com');
-- Time: 5ms
-- Với 5 indexes
INSERT INTO users (name, email) VALUES ('John', 'john@x.com');
-- Time: 12ms (cập nhật 5 indexes)Nguyên tắc: Index các cột bạn đọc thường xuyên, không phải cột bạn ghi thường xuyên.
#Compound Indexes (Nâng Cao)
Đôi khi bạn truy vấn nhiều cột cùng nhau:
SELECT * FROM orders
WHERE user_id = 123
AND status = 'completed'
ORDER BY created_at DESC;Single-column indexes giúp ích một chút, nhưng không đủ.
Tạo compound index:
CREATE INDEX idx_orders_user_status_created
ON orders(user_id, status, created_at DESC);Thứ tự quan trọng!
Index hoạt động từ trái sang phải:
-- Index này: (user_id, status, created_at)
-- Hoạt động tốt cho:
WHERE user_id = ?
WHERE user_id = ? AND status = ?
WHERE user_id = ? AND status = ? ORDER BY created_at
-- Không giúp ích nhiều cho:
WHERE status = ? (bỏ qua cột đầu tiên)
WHERE created_at > ? (bỏ qua hai cột đầu tiên)Nguyên tắc: Đặt cột có tính chọn lọc cao nhất (unique) ở đầu.
#Câu Chuyện Production Có Thật
Bối cảnh:
- API của chúng tôi bắt đầu chậm
- Người dùng phàn nàn
- Sếp không vui
Điều tra:
-- Tìm thấy query chậm này trong logs
SELECT * FROM orders
WHERE user_id = 123
ORDER BY created_at DESC
LIMIT 20;
-- Kiểm tra query plan
EXPLAIN ANALYZE [query trên];
-- Kết quả:
-- Seq Scan on orders (cost=0..50000 rows=1000000)
-- Execution time: 2847msFix:
-- Thêm compound index
CREATE INDEX idx_orders_user_created
ON orders(user_id, created_at DESC);
-- Chạy lại query
EXPLAIN ANALYZE [query];
-- Kết quả:
-- Index Scan using idx_orders_user_created
-- Execution time: 15msTác động:
- Thời gian response: 2.847ms → 15ms (nhanh hơn 189 lần)
- Phàn nàn của người dùng: Dừng lại
- Sự hài lòng của sếp: Được khôi phục
- Thời gian fix: 5 phút
Một index.
Năm phút.
Cứu cả ngày.
#Phần 4: API Response Patterns
#Thảm Họa Dữ Liệu Không Giới Hạn
Để tôi kể cho bạn về một bug tôi đã gây ra trong production.
Ngày đầu tiên của công việc đầu tiên.
Xây dựng endpoint để lấy tất cả users:
@app.get("/users")
def get_users():
users = db.query("SELECT * FROM users")
return usersHoạt động tốt trong development (10 users test).
Deploy lên production (100.000 users thật).
Kết quả:
- Kích thước response: 45MB
- Thời gian response: 38 giây
- Ứng dụng mobile: Crash
- Bộ nhớ server: Cạn kiệt
- Sếp của tôi: Không ấn tượng
Vấn đề:
- Tôi trả về tất cả users
- Không có giới hạn
#Phân Trang: Giải Pháp
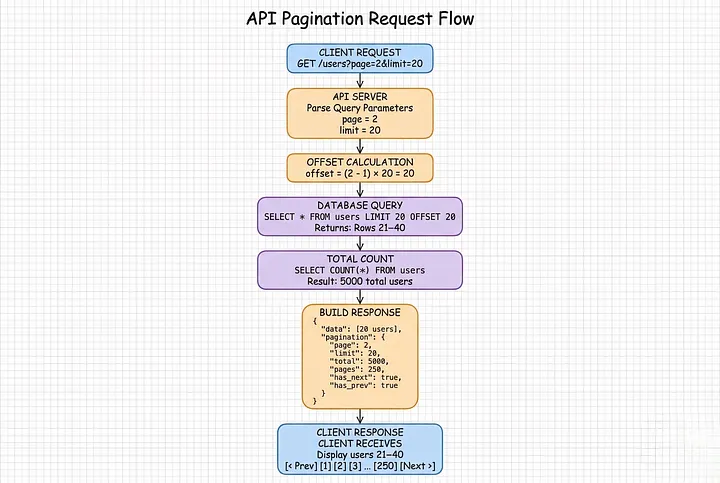
Đừng bao giờ trả về dữ liệu không giới hạn.
Luôn phân trang:
from fastapi import Query
@app.get("/users")
def get_users(
page: int = Query(1, ge=1),
limit: int = Query(20, ge=1, le=100)
):
# Tính offset
offset = (page - 1) * limit
# Lấy users đã phân trang
users = db.query(
"SELECT * FROM users LIMIT %s OFFSET %s",
(limit, offset)
)
# Lấy tổng số (cho UI)
total = db.query("SELECT COUNT(*) FROM users")[0]
return {
"data": users,
"pagination": {
"page": page,
"limit": limit,
"total": total,
"pages": (total + limit - 1) // limit,
"has_next": page * limit < total,
"has_prev": page > 1
}
}Sử dụng:
GET /users?page=1&limit=20 # Trả về users 1-20
GET /users?page=2&limit=20 # Trả về users 21-40
GET /users?page=3&limit=20 # Trả về users 41-60Bây giờ:
- Kích thước response: 2KB (giảm từ 45MB)
- Thời gian response: 200ms (giảm từ 38 giây)
- Ứng dụng mobile: Hoạt động
- Server: Vui vẻ
- Sếp: Bớt khó chịu hơn
#Lọc: Giúp Người Dùng Tìm Thứ Họ Cần
Chỉ phân trang thôi chưa đủ.
Người dùng cần lọc:
@app.get("/orders")
def get_orders(
page: int = Query(1, ge=1),
limit: int = Query(20, ge=1, le=100),
status: Optional[str] = None,
user_id: Optional[int] = None,
min_total: Optional[float] = None
):
# Xây dựng query động
query = "SELECT * FROM orders WHERE 1=1"
params = []
if status:
query += " AND status = %s"
params.append(status)
if user_id:
query += " AND user_id = %s"
params.append(user_id)
if min_total:
query += " AND total >= %s"
params.append(min_total)
# Thêm phân trang
query += " LIMIT %s OFFSET %s"
params.extend([limit, (page - 1) * limit])
orders = db.query(query, params)
total = db.query_count(query.replace("SELECT *", "SELECT COUNT(*)"))
return {
"data": orders,
"pagination": {
"page": page,
"limit": limit,
"total": total
}
}Sử dụng:
GET /orders?status=completed
GET /orders?user_id=123&status=pending
GET /orders?min_total=100&page=2#Sắp Xếp: UX Tốt Hơn
Người dùng mong đợi được sắp xếp:
from enum import Enum
class SortField(str, Enum):
created_at = "created_at"
total = "total"
status = "status"
@app.get("/orders")
def get_orders(
page: int = Query(1, ge=1),
limit: int = Query(20, ge=1, le=100),
sort: SortField = SortField.created_at,
order: str = Query("desc", regex="^(asc|desc)$")
):
# Xác thực và xây dựng query
order_clause = "DESC" if order == "desc" else "ASC"
query = f"""
SELECT * FROM orders
ORDER BY {sort.value} {order_clause}
LIMIT %s OFFSET %s
"""
orders = db.query(query, (limit, (page - 1) * limit))
return {"data": orders, "pagination": {...}}Sử dụng:
GET /orders?sort=created_at&order=desc # Mới nhất trước
GET /orders?sort=total&order=asc # Rẻ nhất trước#Endpoint Hoàn Chỉnh Sẵn Sàng Cho Production
Kết hợp tất cả:
from fastapi import FastAPI, Query, HTTPException
from typing import Optional
from enum import Enum
app = FastAPI()
class OrderStatus(str, Enum):
pending = "pending"
completed = "completed"
cancelled = "cancelled"
class SortField(str, Enum):
created_at = "created_at"
total = "total"
@app.get("/orders")
def get_orders(
# Phân trang
page: int = Query(1, ge=1, description="Page number"),
limit: int = Query(20, ge=1, le=100, description="Items per page"),
# Lọc
status: Optional[OrderStatus] = None,
user_id: Optional[int] = None,
min_total: Optional[float] = None,
max_total: Optional[float] = None,
# Sắp xếp
sort: SortField = SortField.created_at,
order: str = Query("desc", regex="^(asc|desc)$")
):
"""
Lấy orders với phân trang, lọc, và sắp xếp.
Example: GET /orders?status=completed&page=2&limit=20&sort=total&order=desc
"""
# Xây dựng query
query = "SELECT * FROM orders WHERE 1=1"
count_query = "SELECT COUNT(*) FROM orders WHERE 1=1"
params = []
# Thêm bộ lọc
if status:
query += " AND status = %s"
count_query += " AND status = %s"
params.append(status.value)
if user_id:
query += " AND user_id = %s"
count_query += " AND user_id = %s"
params.append(user_id)
if min_total:
query += " AND total >= %s"
count_query += " AND total >= %s"
params.append(min_total)
if max_total:
query += " AND total <= %s"
count_query += " AND total <= %s"
params.append(max_total)
# Thêm sắp xếp
query += f" ORDER BY {sort.value} {order.upper()}"
# Thêm phân trang
offset = (page - 1) * limit
query += " LIMIT %s OFFSET %s"
pagination_params = params + [limit, offset]
# Thực thi queries
try:
orders = db.query(query, pagination_params)
total = db.query(count_query, params)[0]
except Exception as e:
raise HTTPException(status_code=500, detail="Database error")
return {
"data": orders,
"pagination": {
"page": page,
"limit": limit,
"total": total,
"pages": (total + limit - 1) // limit,
"has_next": page * limit < total,
"has_prev": page > 1
},
"filters": {
"status": status,
"user_id": user_id,
"min_total": min_total,
"max_total": max_total
},
"sort": {
"field": sort,
"order": order
}
}#Phần 5: Tổng Kết Tuần 1
#Những Gì Chúng Ta Đã Học
Qua hơn 2.500 từ, chúng ta đã khám phá những kiến thức nền tảng giúp phân biệt code chạy được với hệ thống mở rộng được:
1. Thiết Kế REST API
- URLs dựa trên resource (
/users/{id}) - Ngữ nghĩa HTTP methods (GET, POST, PATCH, DELETE)
- Status codes giao tiếp rõ ràng
- Thiết kế stateless để mở rộng theo chiều ngang
2. Chọn Database
- SQL (PostgreSQL) cho dữ liệu có cấu trúc, ACID, quan hệ
- NoSQL (MongoDB) cho schema linh hoạt, khối lượng lớn
- Phương pháp kết hợp cho hệ thống production
- Ví dụ thực tế từ thương mại điện tử
3. Database Indexes
- Sequential scan vs Index scan (khác biệt hiệu suất 400 lần)
- Khi nào thêm index (WHERE, ORDER BY, JOINs)
- EXPLAIN ANALYZE để tìm index bị thiếu
- Sự đánh đổi (đọc nhanh hơn, ghi chậm hơn)
4. API Response Patterns
- Phân trang (không bao giờ trả về dữ liệu không giới hạn)
- Lọc (giúp người dùng tìm thứ họ cần)
- Sắp xếp (UX tốt hơn)
- Implementation sẵn sàng cho production
#Nền Tảng
Đây không phải là chủ đề nâng cao.
Chúng là chủ đề nền tảng.
Bạn có thể xây dựng tính năng mà không cần chúng.
Nhưng bạn không thể mở rộng mà không có chúng.
Mô hình lặp lại:
- API tốt → Cho phép caching (Tuần 2)
- Database tốt → Cho phép mở rộng (Tuần 4)
- Response tốt → Cho phép hiệu suất (Tuần 5)
#Những Sai Lầm Thường Gặp Cần Tránh
Tôi đã mắc tất cả những lỗi này. Bạn không cần phải thế:
- Trả về tất cả bản ghi mà không phân trang (làm crash app production đầu tiên của tôi)
- Chọn MongoDB vì "nó hiện đại" (mất 3 tuần để migrate về PostgreSQL)
- Không bao giờ chạy EXPLAIN ANALYZE (bỏ lỡ cải thiện hiệu suất 100x)
- Bỏ qua HTTP status codes (làm cho việc debug không thể)
#Tuần Sau: Caching & Hiệu Suất
Xem trước Tuần 2:
- Redis caching fundamentals
- Chiến lược cache invalidation (bài toán khó)
- CDN và edge caching
- Tối ưu query ngoài indexes
- Cache stampede và thundering herd
Tôi sẽ đề cập:
- Khi nào cache (và khi nào KHÔNG)
- Cache-aside vs write-through patterns
- Kiến trúc caching production thực tế
- Cách chúng tôi giảm 80% tải database
#Kết Luận
Tuần 1 đã hoàn thành.
Bạn giờ đã có nền tảng.
Nhưng biết thôi chưa đủ.