
Mở Rộng Database Trong Production: Từ 1 Server Đến 500 Replicas

#Cách Instagram, GitHub, và Shopify scale PostgreSQL cho hàng tỷ người dùng (kèm hướng dẫn triển khai hoàn chỉnh)

#Giới Thiệu
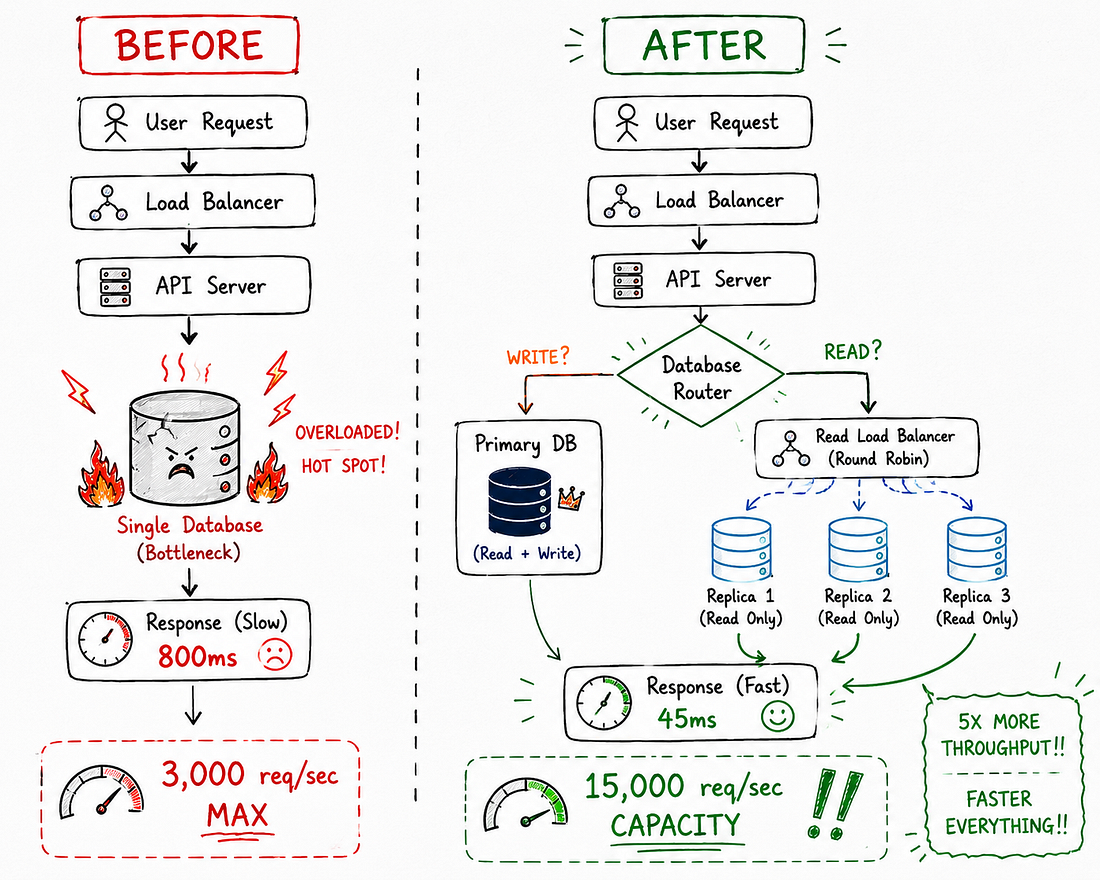
API của chúng tôi đang hấp hối ở 3,000 requests mỗi giây.
Database CPU: 87%.
Thời gian phản hồi query: 800ms.
Người dùng phàn nàn về tải trang chậm.
Chúng tôi có hai lựa chọn:
- Vertical scaling: Nâng cấp lên database server $5,000/tháng
- Horizontal scaling: Thêm read replicas với tổng chi phí $600/tháng
Chúng tôi chọn replication.
Trong vòng 48 giờ:
- Thời gian phản hồi giảm từ 800ms xuống 45ms (nhanh hơn 17 lần)
- Database CPU giảm từ 87% xuống 22% (giảm 4 lần)
- API throughput tăng từ 3,000 lên 15,000 req/sec (cải thiện 5 lần)
Bài viết này bao gồm mọi thứ chúng tôi đã học được:
PostgreSQL replication setup, read-write splitting patterns, xử lý replication lag, automatic failover với Patroni, và kiến trúc production hoàn chỉnh đang vận hành các ứng dụng phục vụ hàng triệu người dùng.
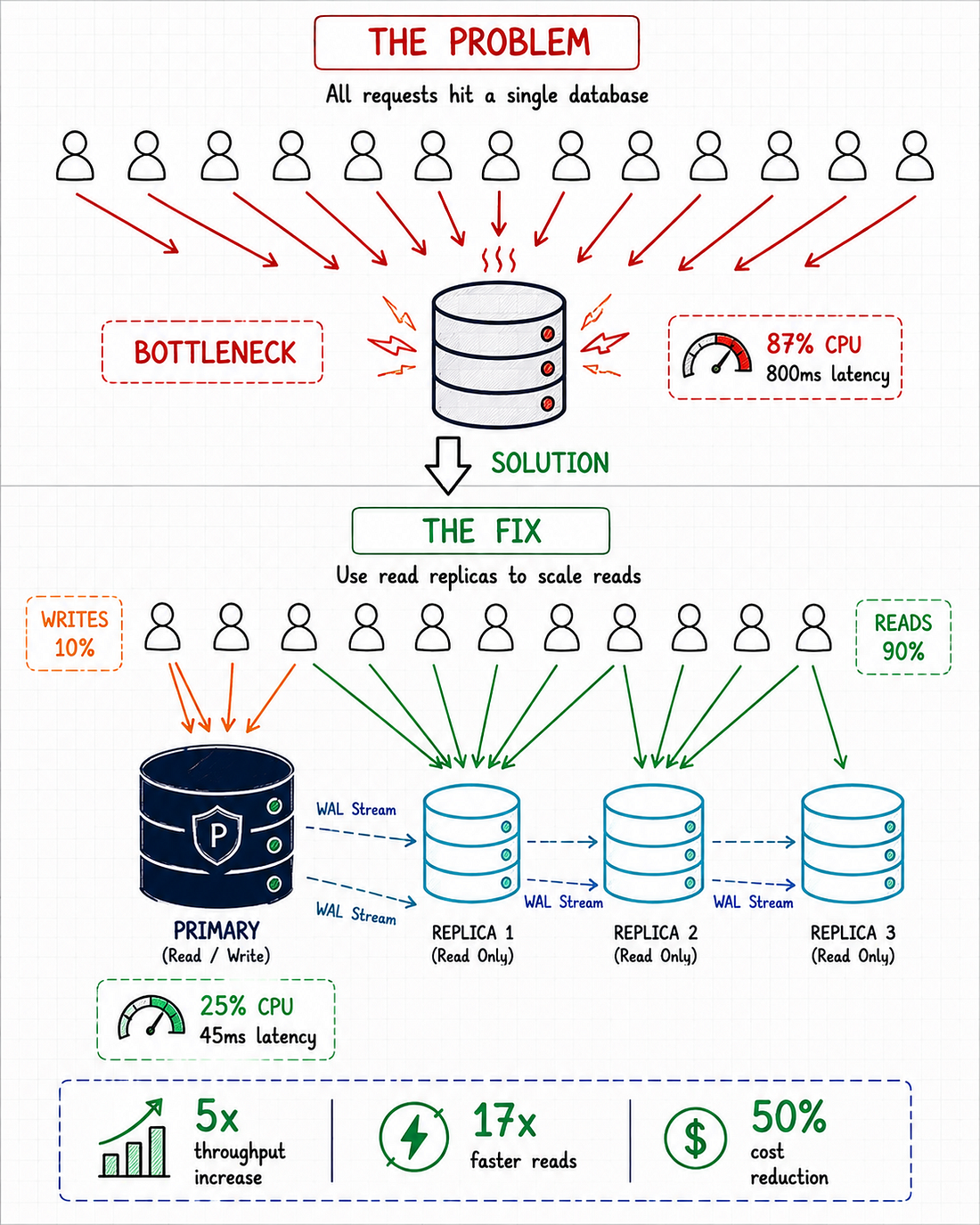
#Tại Sao Database Trở Thành Nút Thắt Cổ Chai
Hầu hết ứng dụng web đều theo luồng request đơn giản này:
User → API Server → Database → Response
Khi bạn bắt đầu, một database đơn lẻ xử lý mọi thứ tốt.
Nhưng khi bạn phát triển, database trở thành thành phần chậm nhất trong stack của bạn.
Tại sao database vốn dĩ chậm:
Disk I/O bottleneck:
- Ngay cả SSD hiện đại cũng chậm hơn RAM 100,000 lần.
- Mọi query không thể phục vụ từ memory đều phải truy cập disk.
Query complexity:
- JOINs qua nhiều bảng, aggregations, sorting — những thao tác này tốn rất nhiều tài nguyên tính toán, đặc biệt trên dataset lớn.
Network latency:
- Nếu database chạy trên server riêng (điều nên làm), mỗi query thêm 10-50ms network round-trip time.
Connection overhead:
- Thiết lập kết nối database mất 50-100ms.
- Ngay cả với connection pooling, vẫn có overhead.
Số liệu production thực tế từ e-commerce API của chúng tôi:
Phân tích truy vấn hồ sơ người dùng đơn giản:
- Network đến database: 15ms
- Thực thi database query: 450ms
- Truyền result set: 35ms
- JSON serialization: 100ms
- Tổng: 600ms
Với 1,000 người dùng đồng thời, instance PostgreSQL đơn của chúng tôi bị quá tải. Database CPU đạt 87%, và thời gian phản hồi xuống cấp đến 800ms trong giờ cao điểm.
Hiểu biết cốt lõi: 90% ứng dụng web là read-heavy.
Nhìn vào mẫu lưu lượng của chúng tôi:
- Product page views: 45,000 requests/giờ (reads)
- Search queries: 28,000 requests/giờ (reads)
- User profile loads: 15,000 requests/giờ (reads)
- Checkout transactions: 2,000 requests/giờ (writes)
- Cart updates: 3,500 requests/giờ (writes)
Read traffic: 88,000 req/giờ (94%)
Write traffic: 5,500 req/giờ (6%)
Mẫu read-heavy này phổ biến ở hầu hết các ứng dụng.
- Twitter là 99% reads.
- Instagram là 95% reads.
- Ngay cả ứng dụng write-heavy như Slack vẫn là 70% reads.
Giải pháp: Tách riêng read và write workloads bằng database replication.
#Kiến Trúc Database Replication
Database replication nghĩa là chạy nhiều bản sao của database của bạn:
Primary (Master) database: Xử lý tất cả write operations (INSERT, UPDATE, DELETE)
Replica (Slave) databases: Xử lý read operations (SELECT queries)
Primary liên tục stream tất cả thay đổi đến replicas, giữ chúng đồng bộ.
Cách replication hoạt động dưới nắp capo:
- Application gửi write đến primary database
- Primary thực thi write và cập nhật dữ liệu
- Primary ghi thay đổi vào Write-Ahead Log (WAL)
- WAL stream được gửi đến tất cả replicas
- Replicas áp dụng các thay đổi WAL vào dữ liệu của chúng
- Replicas bây giờ nhất quán với primary (với độ trễ nhỏ)
PostgreSQL sử dụng streaming replication:
- Primary database liên tục stream WAL (Write-Ahead Log) records đến replicas.
- WAL chứa mọi thay đổi database — mỗi INSERT, UPDATE, DELETE operation ở dạng nhị phân.
Replicas nhận stream này, áp dụng các thay đổi vào file dữ liệu cục bộ, và duy trì đồng bộ với primary.
Replication lag điển hình:
- 100-500ms dưới tải bình thường.
- Điều này nghĩa là dữ liệu ghi vào primary mất 100-500ms để xuất hiện trên replicas.
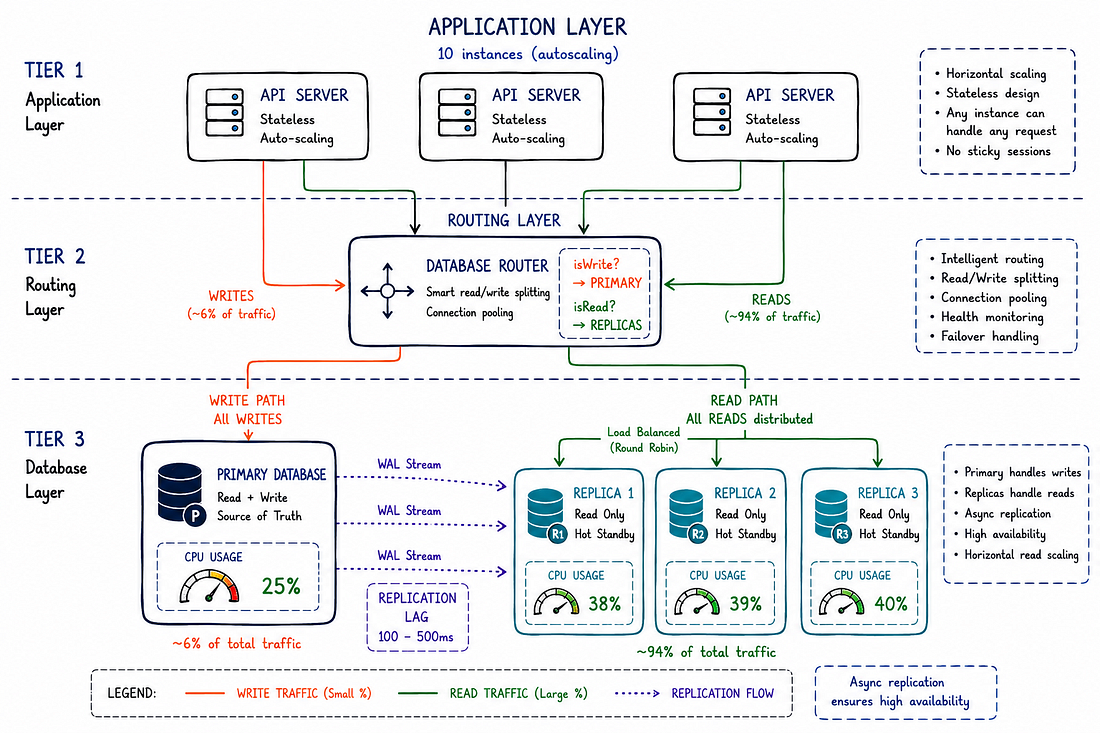
Thiết lập production của chúng tôi sau khi triển khai replication:
1 Primary database (chỉ writes)
↓
Nhân bản đến
↓
3 Read replicas (chỉ reads)
Phân phối lưu lượng:
- Primary xử lý 5,500 writes/giờ (6% lưu lượng)
- Mỗi replica xử lý ~29,000 reads/giờ (31% mỗi cái)
- Tổng dung lượng: 93,500 requests/giờ
Cải thiện hiệu suất:
| Metric | Trước | Sau | Cải thiện |
|---|---|---|---|
| Max throughput | 3,000 req/sec | 15,000 req/sec | 5x |
| Avg read latency | 600ms | 45ms | nhanh hơn 13x |
| Avg write latency | 120ms | 85ms | nhanh hơn 1.4x |
| Database CPU | 87% | Primary: 22%, Replicas: 38% | giảm 4x |
| Chi phí hàng tháng | $1,200 | $600 | tiết kiệm 50% |
Phân tích chi phí:
Trước: 1 instance database lớn (8 vCPU, 32GB RAM) = $1,200/tháng
Sau:
- 1 primary (2 vCPU, 8GB RAM) = $150/tháng
- 3 replicas (2 vCPU, 8GB RAM mỗi cái) = $450/tháng
- Tổng: $600/tháng
Chúng tôi cắt giảm một nửa chi phí trong khi tăng dung lượng gấp 5 lần.
Điều này hiệu quả vì chúng tôi định cỡ đúng infrastructure — primary chỉ cần xử lý 6% lưu lượng (writes), nên không cần phải quá lớn.
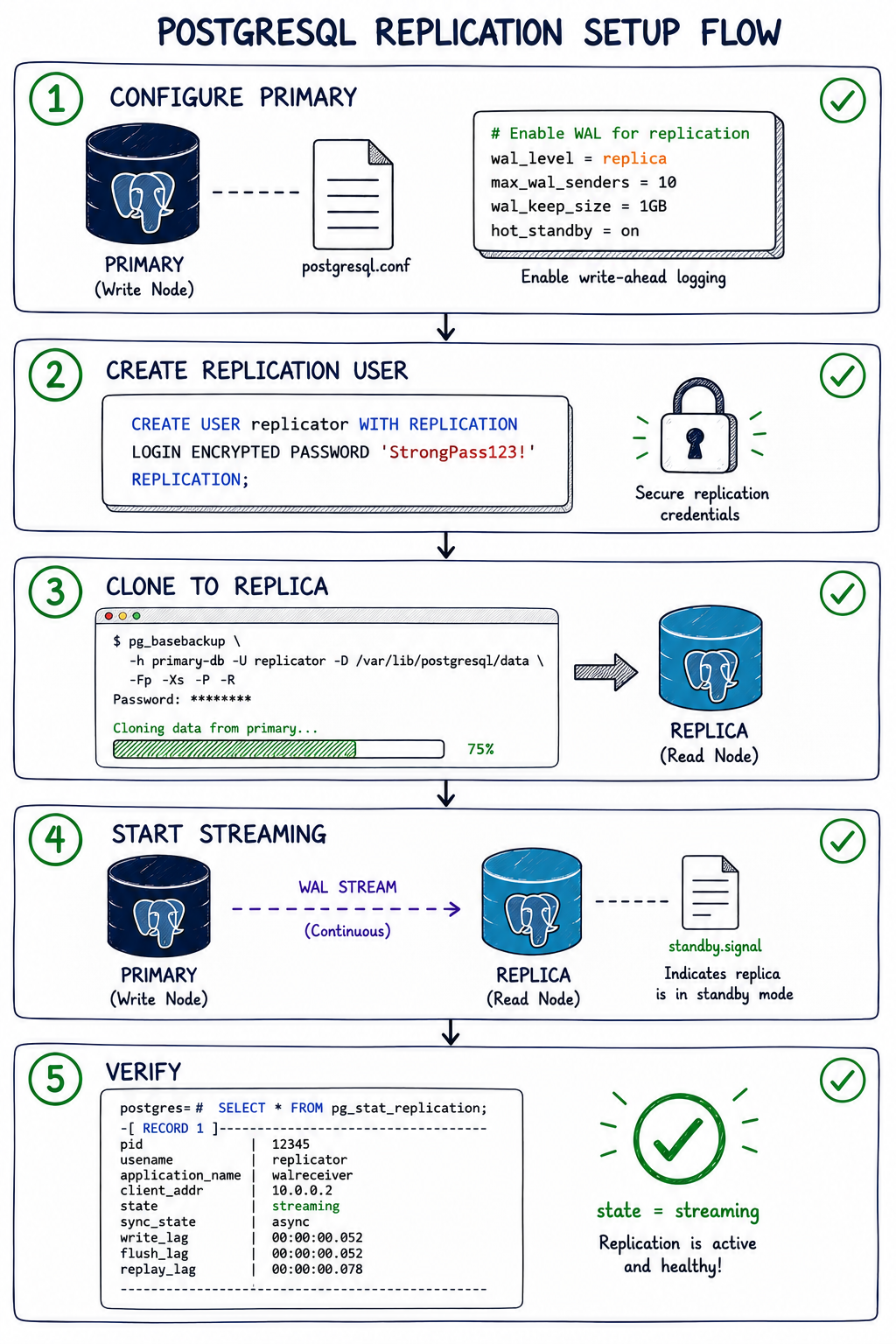
#Thiết Lập PostgreSQL Replication (Từng Bước)
Đây là thiết lập production hoàn chỉnh chúng tôi sử dụng.
Hoạt động với PostgreSQL 12+.
#Bước 1: Cấu Hình Primary Database
Sửa /etc/postgresql/14/main/postgresql.conf:
wal_level = replica
max_wal_senders = 10
wal_keep_size = 1 GB
archive_mode = on
archive_command = 'cp %p /var/lib/postgresql/wal_archive/%f'Các setting này làm gì:
wal_level = replica — bật WAL streaming đến replicas (mặc định là minimal, không stream)
max_wal_senders = 10 — cho phép tối đa 10 kết nối replica đồng thời
wal_keep_size = 1GB — giữ lại 1GB WAL trên primary để replicas có thể bắt kịp nếu bị tụt lại
#Bước 2: Tạo Replication User
Trên primary database:
CREATE USER replicator
WITH REPLICATION
ENCRYPTED PASSWORD 'your_secure_password_here';Sửa /etc/postgresql/14/main/pg_hba.conf để cho phép kết nối replica:
host replication replicator 10.0.1.0/24 md5Điều này cho phép bất kỳ server nào trong subnet 10.0.1.0/24 kết nối với tư cách replication user.
Khởi động lại PostgreSQL trên primary:
sudo systemctl restart postgresql#Bước 3: Thiết Lập Replica Servers
Trên mỗi replica server, dừng PostgreSQL và clone dữ liệu từ primary:
sudo systemctl stop postgresql
sudo rm -rf /var/lib/postgresql/14/main/*
sudo -u postgres pg_basebackup \
-h 10.0.1.10 \
-U replicator \
-D /var/lib/postgresql/14/main \
-P -v -R -X stream -C -S replica1_slot
sudo systemctl start postgresqlCác flag này làm gì:
-h 10.0.1.10 — địa chỉ IP của primary database
-U replicator — sử dụng replication user chúng ta đã tạo
-D /var/lib/postgresql/14/main — thư mục dữ liệu đích
-P — hiển thị tiến trình
-v — verbose output
-R — tạo file standby.signal (báo cho PostgreSQL đây là replica)
-X stream — stream WAL trong quá trình backup
-C — tạo replication slot
-S replica1_slot — tên replication slot (ngăn xóa WAL)
Flag -R tự động tạo cấu hình chính xác cho replica, bao gồm file standby.signal và cài đặt kết nối.
#Bước 4: Xác Minh Replication
Trên primary, kiểm tra trạng thái replication:
SELECT
client_addr,
state,
sent_lsn,
write_lsn,
flush_lsn,
replay_lsn,
sync_state
FROM pg_stat_replication;Kết quả mong đợi:
client_addr | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | sync_state
------------+----------+----------+-----------+-----------+------------+-----------
10.0.1.11 | streaming| 0/5000140| 0/5000140 | 0/5000140 | 0/5000140 | async
10.0.1.12 | streaming| 0/5000140| 0/5000140 | 0/5000140 | 0/5000140 | async
10.0.1.13 | streaming| 0/5000140| 0/5000140 | 0/5000140 | 0/5000140 | asyncCác cột này nghĩa là gì:
state = streaming — replica đã kết nối và đang nhận WAL
sent_lsn — log sequence number đã gửi từ primary
replay_lsn — log sequence number đã áp dụng trên replica
Nếu sent_lsn ≈ replay_lsn, replication đã bắt kịp (tốt!)
Nếu chúng khác nhau đáng kể, replication đang bị lag (cần điều tra hiệu suất network hoặc replica)
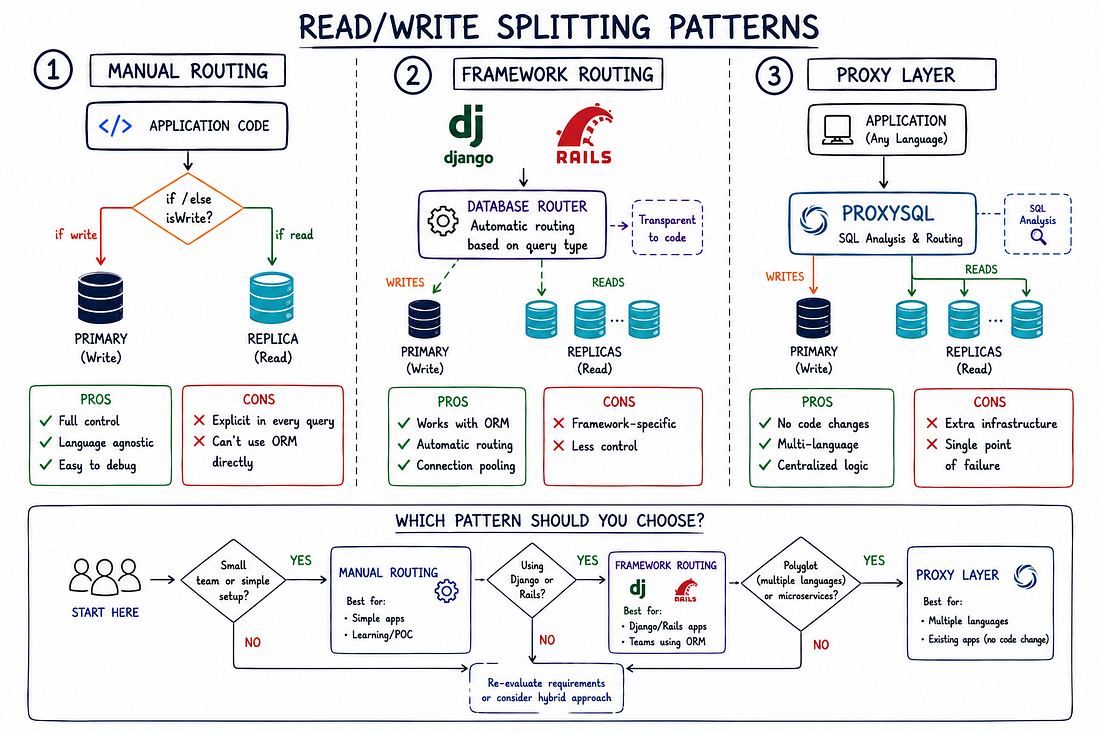
#Application-Level Read-Write Splitting
Replication vô ích nếu ứng dụng của bạn vẫn gửi tất cả queries đến primary.
Bạn cần định tuyến reads đến replicas và writes đến primary.
Ba mẫu phổ biến:
#Pattern 1: Manual Routing (Kiểm Soát Tối Đa)
import random
from sqlalchemy import create_engine
class DatabaseRouter:
def __init__(self):
self.primary = create_engine(
'postgresql://user:pass@10.0.1.10:5432/mydb',
pool_size=20
)
self.replicas = [
create_engine('postgresql://user:pass@10.0.1.11:5432/mydb', pool_size=50),
create_engine('postgresql://user:pass@10.0.1.12:5432/mydb', pool_size=50),
create_engine('postgresql://user:pass@10.0.1.13:5432/mydb', pool_size=50)
]
self.replica_index = 0
def execute_write(self, query, params=None):
"""Tất cả writes đến primary"""
with self.primary.connect() as conn:
return conn.execute(query, params)
def execute_read(self, query, params=None):
"""Reads phân phối qua replicas (round-robin)"""
replica = self.replicas[self.replica_index]
self.replica_index = (self.replica_index + 1) % len(self.replicas)
with replica.connect() as conn:
return conn.execute(query, params)
router = DatabaseRouter()
router.execute_write("INSERT INTO users (name, email) VALUES (?, ?)",
('Alice', 'alice@example.com'))
router.execute_write("UPDATE users SET active = true WHERE id = 123")
user = router.execute_read("SELECT * FROM users WHERE id = 123")
products = router.execute_read("SELECT * FROM products WHERE category = 'electronics'")Ưu điểm: Kiểm soát hoàn toàn logic định tuyến, hoạt động với mọi framework, dễ debug
Nhược điểm: Yêu cầu quyết định rõ ràng trong mỗi query (không thể dùng ORM trực tiếp)
#Pattern 2: Framework-Level Routing (Ví dụ Django)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydb',
'HOST': '10.0.1.10',
'PORT': '5432',
},
'replica1': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydb',
'HOST': '10.0.1.11',
'PORT': '5432',
},
'replica2': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydb',
'HOST': '10.0.1.12',
'PORT': '5432',
},
'replica3': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydb',
'HOST': '10.0.1.13',
'PORT': '5432',
}
}
class PrimaryReplicaRouter:
def db_for_read(self, model, **hints):
"""Gửi reads đến replica ngẫu nhiên"""
return random.choice(['replica1', 'replica2', 'replica3'])
def db_for_write(self, model, **hints):
"""Gửi writes đến primary"""
return 'default'
def allow_relation(self, obj1, obj2, **hints):
return True
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""Chỉ chạy migration trên primary"""
return db == 'default'
DATABASE_ROUTERS = ['myapp.routers.PrimaryReplicaRouter']from django.contrib.auth.models import User
# Write → primary
User.objects.create(username='alice', email='alice@example.com')
# Read → replica
users = User.objects.filter(is_active=True)Ưu điểm: Trong suốt với application code, hoạt động liền mạch với ORM, framework xử lý connection pooling
Nhược điểm: Phụ thuộc framework, ít kiểm soát logic định tuyến
#Pattern 3: Proxy Layer (ProxySQL)
Sử dụng database proxy tự động định tuyến queries dựa trên phân tích SQL:
Application (kết nối đến ProxySQL trên port 6033)
↓
ProxySQL phân tích query
↓
├─→ SELECT queries → Replicas (load balanced)
└─→ INSERT/UPDATE/DELETE → PrimaryCấu hình ProxySQL:
INSERT INTO mysql_servers(hostgroup_id, hostname, port, max_connections) VALUES
(0, '10.0.1.10', 3306, 100),
(1, '10.0.1.11', 3306, 200),
(1, '10.0.1.12', 3306, 200),
(1, '10.0.1.13', 3306, 200);
INSERT INTO mysql_query_rules(rule_id, match_pattern, destination_hostgroup, apply) VALUES
(1, '^SELECT.*FOR UPDATE', 0, 1),
(2, '^SELECT', 1, 1),
(3, '.*', 0, 1);
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;Application kết nối đến ProxySQL như một database thông thường:
db = create_engine('postgresql://user:pass@proxysql:6033/mydb')
db.execute("SELECT * FROM users") # → replica
db.execute("INSERT INTO users VALUES ...") # → primary
db.execute("UPDATE users SET ...") # → primaryƯu điểm: Không cần thay đổi application code, hoạt động với mọi ngôn ngữ lập trình, centralized routing logic, built-in query caching
Nhược điểm: Thêm infrastructure cần duy trì, single point of failure (có thể giảm thiểu với HA setup), độ trễ nhẹ (~1-2ms)
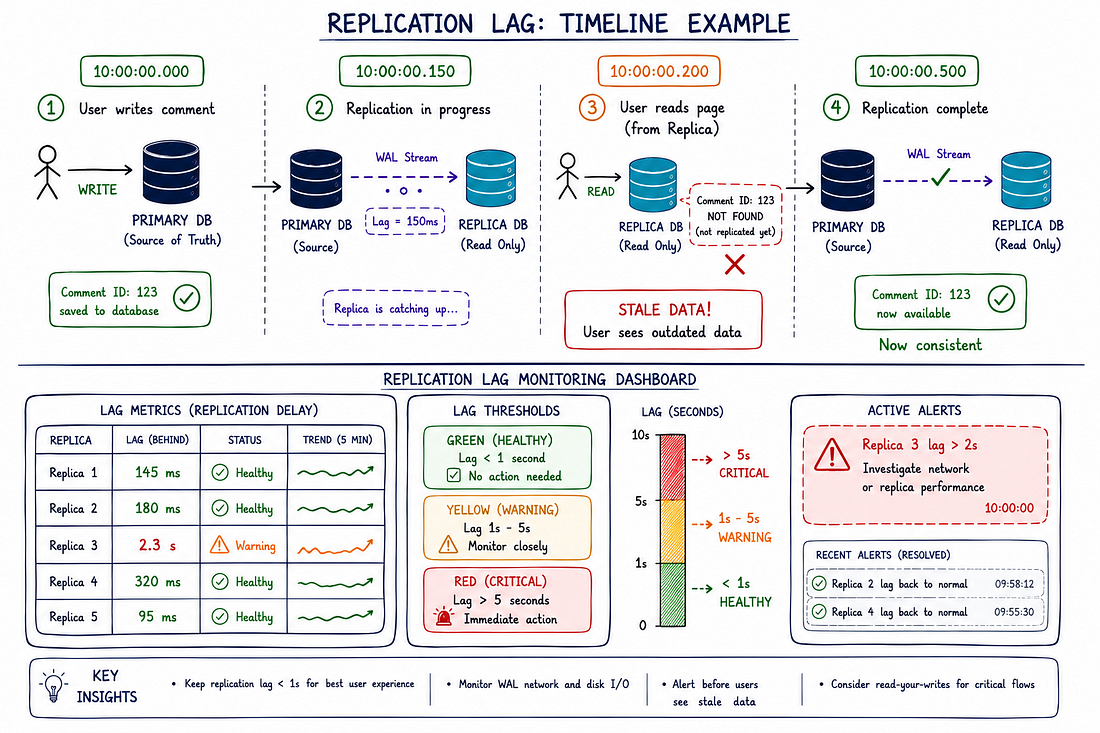
#Xử Lý Replication Lag
Replication lag là độ trễ thời gian giữa khi dữ liệu được ghi vào primary và khi nó xuất hiện trên replicas.
Replication lag điển hình: 100-500ms trong điều kiện bình thường
Vấn đề này gây ra:
Timeline:
10:00:00.000 → User đăng comment (write vào primary)
10:00:00.100 → Write xác nhận, user được redirect
10:00:00.150 → Trình duyệt user yêu cầu thread comment (đọc từ replica)
10:00:00.200 → Replica chưa có comment (lag = 200ms)
10:00:00.250 → User thấy trang KHÔNG có comment của họ
10:00:00.500 → Replication bắt kịp
10:00:00.600 → User refresh, BÂY GIỜ mới thấy commentĐiều này tạo ra trải nghiệm người dùng tồi tệ.
Người dùng nghĩ hành động của họ thất bại.
#Giải Pháp 1: Read-Your-Writes Consistency
Sau khi user ghi dữ liệu, đảm bảo các lần đọc tiếp theo của họ đến từ primary trong một khoảng thời gian ngắn:
import time
from collections import defaultdict
class SmartDatabaseRouter:
def __init__(self):
self.primary = create_engine('postgresql://primary:5432/db')
self.replicas = [
create_engine('postgresql://replica1:5432/db'),
create_engine('postgresql://replica2:5432/db'),
create_engine('postgresql://replica3:5432/db')
]
self.recent_writes = defaultdict(float)
self.write_window = 5
def execute_write(self, user_id, query, params=None):
"""Thực thi write và theo dõi thời gian ghi của user"""
result = self.primary.execute(query, params)
self.recent_writes[user_id] = time.time()
return result
def execute_read(self, user_id, query, params=None):
"""Định tuyến read dựa trên lịch sử ghi gần đây"""
last_write_time = self.recent_writes.get(user_id, 0)
time_since_write = time.time() - last_write_time
if time_since_write < self.write_window:
return self.primary.execute(query, params)
replica = random.choice(self.replicas)
return replica.execute(query, params)
router = SmartDatabaseRouter()
router.execute_write(123, "INSERT INTO comments ...")
comments = router.execute_read(123, "SELECT * FROM comments ...") # → primary
comments = router.execute_read(123, "SELECT * FROM comments ...") # → replica (sau 5s)Kết quả: User luôn thấy writes của chính họ ngay lập tức, trong khi reads của user khác vẫn được phân phối đến replicas.
#Giải Pháp 2: Giám Sát và Cảnh Báo Lag Cao
Thiết lập giám sát để phát hiện replication lag trước khi nó trở thành vấn đề:
import psycopg2
def check_replication_lag():
"""Kiểm tra lag trên tất cả replicas"""
primary_conn = psycopg2.connect("host=primary dbname=mydb")
with primary_conn.cursor() as cursor:
cursor.execute("""
SELECT
client_addr,
EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp())) AS lag_seconds,
pg_wal_lsn_diff(sent_lsn, replay_lsn) AS lag_bytes
FROM pg_stat_replication;
""")
for row in cursor.fetchall():
replica_ip, lag_seconds, lag_bytes = row
if lag_seconds > 5:
alert(f"Replica {replica_ip} lag: {lag_seconds}s (CRITICAL)")
elif lag_bytes > 100 * 1024 * 1024:
alert(f"Replica {replica_ip} lag: {lag_bytes/1024/1024}MB (WARNING)")Replication khỏe mạnh:
- Lag time: < 1 giây
- Lag bytes: < 10MB
Dấu hiệu cảnh báo:
- Lag time: 1-5 giây
- Lag bytes: 10-100MB
Vấn đề nghiêm trọng:
- Lag time: > 5 giây
- Lag bytes: > 100MB
Nguyên nhân phổ biến của replication lag:
- Phần cứng replica chậm: Replica không áp dụng WAL đủ nhanh (nâng cấp CPU/disk)
- Tắc nghẽn mạng: Luồng WAL bị giới hạn (nâng cấp băng thông mạng)
- Batch writes lớn: Primary ghi 1GB dữ liệu trong một transaction (chia thành các transaction nhỏ hơn)
- Replica đang chạy queries nặng: Long-running SELECT chặn áp dụng WAL (thêm replicas)
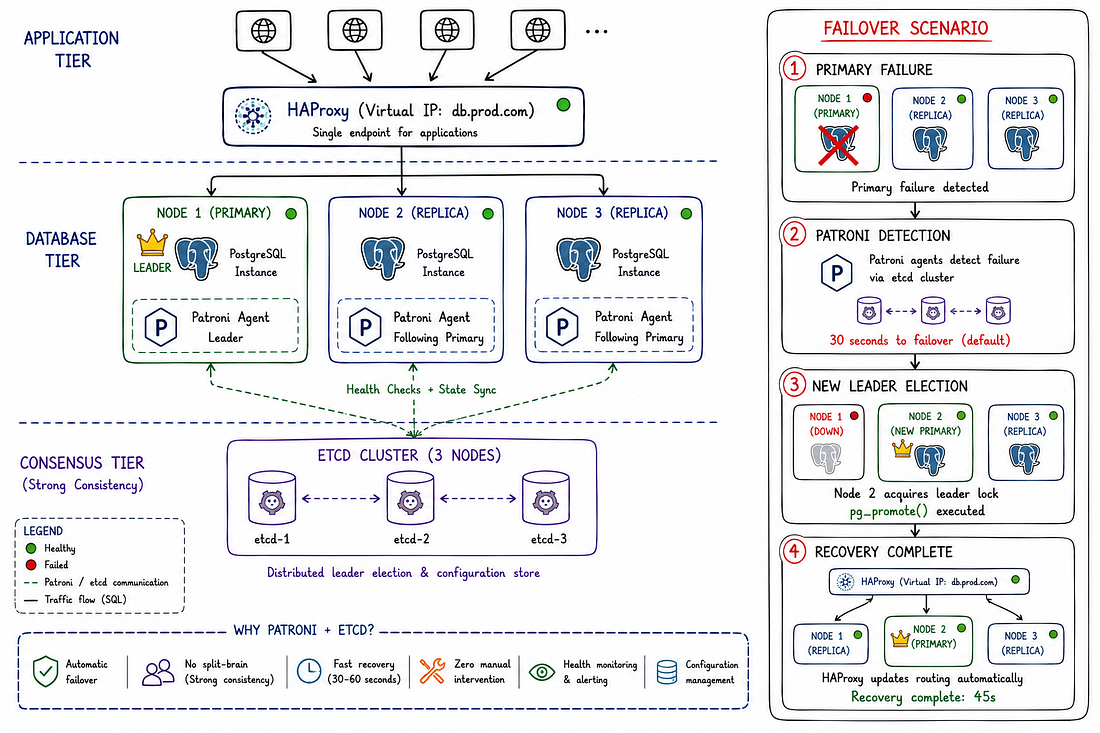
#Database Failover và High Availability
Primary database của bạn cuối cùng sẽ crash.
- Phần cứng hỏng.
- Mạng bị phân chia.
- Ổ đĩa đầy.
- Bạn cần một kế hoạch.
Quy trình failover thủ công:
Khi primary crash lúc 2 giờ sáng:
ssh replica1.db.com
sudo -u postgres psql -c "SELECT pg_promote();"
ansible-playbook restart_app_servers.yml
psql -h replica1 -c "INSERT INTO health_check VALUES (NOW());"Downtime với failover thủ công: 10-30 phút (tùy vào ai đang trực và phản ứng nhanh thế nào)
Điều này từng hiệu quả với chúng tôi, nhưng 30 phút downtime rất đắt:
- Mất doanh thu: ~$5,000 (cho ứng dụng e-commerce của chúng tôi)
- Ticket hỗ trợ khách hàng: 200+
- Danh tiếng bị tổn hại
- Mất lòng tin
Chúng tôi cần automatic failover.
#Automatic Failover với Patroni
Patroni là giải pháp high-availability giám sát PostgreSQL và tự động thăng cấp replicas khi primary gặp sự cố.
Cách Patroni hoạt động:
- Patroni chạy trên mỗi database server
- Tất cả Patroni instances sử dụng etcd/Consul để distributed consensus
- Một node giữ "leader lock" trong etcd (đây là primary)
- Patroni liên tục kiểm tra sức khỏe primary (mỗi 10 giây)
- Nếu primary không phản hồi (3 lần kiểm tra thất bại = 30 giây), leader lock được giải phóng
- Patroni trên các replicas chạy đua để giành lock
- Người thắng tự thăng cấp thành primary mới
- Các replicas khác bắt đầu theo dõi primary mới
Cấu hình Patroni:
scope: postgres-cluster
name: node1
restapi:
listen: 0.0.0.0:8008
connect_address: 10.0.1.11:8008
etcd:
host: etcd.internal:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 30
maximum_lag_on_failover: 1048576
initdb:
- encoding: UTF8
- data-checksums
postgresql:
listen: 0.0.0.0:5432
connect_address: 10.0.1.11:5432
data_dir: /var/lib/postgresql/14/main
pgpass: /tmp/pgpass
authentication:
replication:
username: replicator
password: secure_password
superuser:
username: postgres
password: secure_password
parameters:
max_connections: 100
shared_buffers: 2GB
effective_cache_size: 6GB
wal_level: replica
max_wal_senders: 10Khởi động Patroni trên tất cả các node:
sudo systemctl enable patroni
sudo systemctl start patroniKiểm tra failover:
ssh primary.db.com
sudo systemctl stop postgresql
journalctl -u patroni -fDowntime với Patroni: 30-60 giây (hoàn toàn tự động)
Kết quả production:
Chúng tôi đã có 3 sự cố primary không mong muốn trong năm qua:
- Sự cố 1: Lỗi phần cứng, Patroni thăng cấp replica trong 42 giây
- Sự cố 2: Đĩa đầy, thăng cấp trong 38 giây
- Sự cố 3: Phân mạng, thăng cấp trong 51 giây
Downtime trung bình mỗi sự cố: 43 giây
Tổng downtime không mong muốn (hàng năm): 2.2 phút
Availability: 99.9996% (chúng tôi đặt mục tiêu 99.95%, đang vượt xa)
Kiến trúc HA hoàn chỉnh của chúng tôi:
HAProxy (Virtual IP: db.prod.com:5432)
↓
├─→ node1 (Primary) ← Patroni quản lý
├─→ node2 (Replica)
└─→ node3 (Replica)
↑
Patroni sử dụng etcd cho consensus
↓
etcd cluster (3 nodes cho quorum)Application kết nối đến HAProxy virtual IP.
HAProxy định tuyến đến node mà Patroni đánh dấu là primary.
Khi failover xảy ra, HAProxy tự động định tuyến đến primary mới.
#Kiến Trúc Production Hoàn Chỉnh
Đây là thiết lập production cuối cùng của chúng tôi phục vụ 50,000 người dùng đồng thời:
Users
↓
Load Balancer (HAProxy)
↓
API Servers (10 instances, autoscaling)
↓
Application Database Router
↓
├─→ WRITES → HAProxy (db-writes.prod.com)
│ ↓
│ Primary DB (Patroni managed)
│
└─→ READS → HAProxy (db-reads.prod.com)
↓
Load balanced across 3 replicas
Patroni + etcd quản lý failover
Datadog giám sát replication lagThông số infrastructure:
Primary database:
- 4 vCPU, 16GB RAM
- 500GB SSD
- AWS RDS equivalent: db.m5.xlarge
- Chi phí: $250/tháng
Replicas (3x):
- 4 vCPU, 16GB RAM mỗi cái
- 500GB SSD mỗi cái
- AWS RDS equivalent: 3x db.m5.xlarge
- Chi phí: $750/tháng tổng
etcd cluster (3 nodes):
- 2 vCPU, 4GB RAM mỗi cái
- Chi phí: $150/tháng tổng
Tổng chi phí hàng tháng: $1,150
Chỉ số hiệu suất:
| Metric | Giá trị |
|---|---|
| Peak throughput | 15,000 req/sec |
| Average read latency | 45ms (p95: 120ms) |
| Average write latency | 85ms (p95: 200ms) |
| Database CPU (primary) | 25% trung bình, 60% peak |
| Database CPU (replicas) | 40% trung bình, 75% peak |
| Replication lag | 150ms trung bình, 800ms p99 |
| Uptime (hàng năm) | 99.96% |
Giám sát và cảnh báo:
Chúng tôi giám sát các metric này trong Datadog:
# Replication lag (kiểm tra mỗi 10 giây)
if lag_seconds > 5:
alert_pagerduty("CRITICAL: Replication lag > 5 seconds")
elif lag_seconds > 2:
alert_slack("WARNING: Replication lag > 2 seconds")
# Replica health (kiểm tra mỗi 30 giây)
if replica_count < 2:
alert_pagerduty("CRITICAL: Less than 2 replicas available")
# Primary failover (cảnh báo ngay lập tức)
if primary_changed:
alert_slack("INFO: Primary database failover to {new_primary}")
# Connection pool exhaustion
if connection_pool_usage > 90%:
alert_slack("WARNING: Connection pool at {usage}%")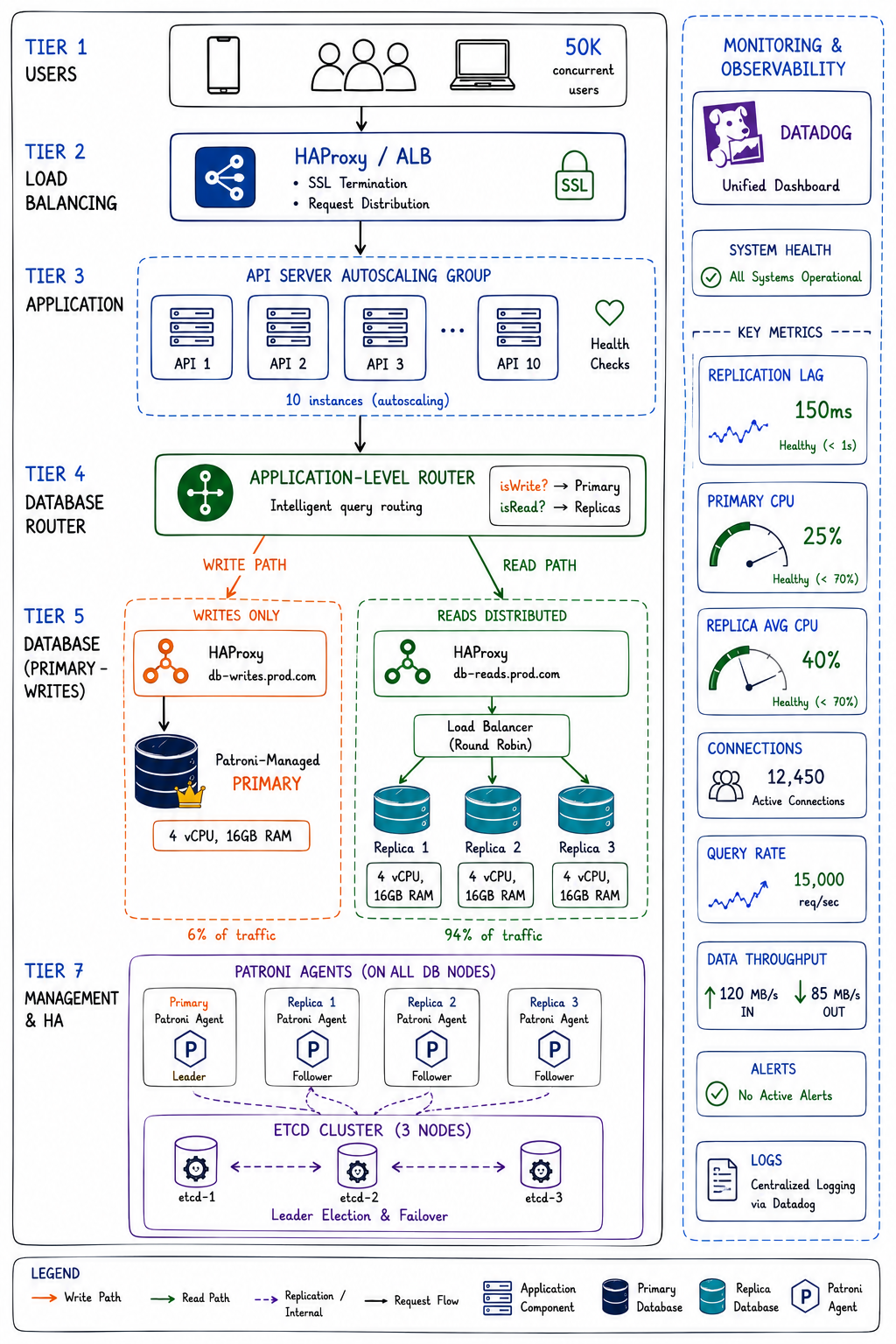
#Ví Dụ Thực Tế
Instagram (PostgreSQL):
- 500+ read replicas toàn cầu
- Multi-region replication cho độ trễ thấp
- Sharding cho người dùng nóng (celebrities)
- Custom replication monitoring và failover
GitHub (MySQL):
- 50+ MySQL replicas
- Orchestrator cho automatic failover
- Vitess cho sharding ở quy mô lớn
- Read replicas ở mỗi khu vực chính
Shopify (PostgreSQL):
- 100+ PostgreSQL replicas
- PgBouncer cho connection pooling
- Custom Ruby router cho read-write splitting
- Resiliency testing với chaos engineering
Các mẫu chung ở cả ba:
- Nhiều replicas: Nhiều replicas = dung lượng đọc lớn hơn + phân phối địa lý
- Automatic failover: Không thể dựa vào con người lúc 3 giờ sáng
- Connection pooling: Databases có giới hạn kết nối (thường 100-500)
- Application-level routing: Database không biết queries nào nên đi đâu
- Giám sát tích cực: Biết về vấn đề trước khi người dùng phát hiện
#Các Sai Lầm Thường Gặp Cần Tránh
1. Không giám sát replication lag
Bạn sẽ chỉ phát hiện vấn đề lag khi người dùng phàn nàn về dữ liệu bị thiếu. Giám sát lag liên tục và cảnh báo khi vượt ngưỡng.
2. Over-replicating quá sớm
Chúng tôi bắt đầu với 1 primary + 1 replica.
Đừng nhảy lên 10 replicas khi bạn có 100 người dùng. Scale khi cần.
3. Quên connection pooling
Với 10 app servers mỗi cái mở 20 kết nối, đó là 200 kết nối database.
PostgreSQL mặc định 100 max connections.
Sử dụng PgBouncer hoặc điều chỉnh max_connections.
4. Không kiểm tra failover
Kiểm tra failover hàng quý.
Chủ động kill primary và xác minh:
- Replica promotion hoạt động
- Application tự động kết nối lại
- Không mất dữ liệu
- Cảnh báo giám sát kích hoạt chính xác
5. Bỏ qua write scaling
Replication giúp với reads, không phải writes.
Nếu bạn write-heavy (logging, analytics), bạn cần sharding hoặc kiến trúc khác.
#Production Checklist
Trước khi triển khai database replication lên production:
Lập kế hoạch:
- [ ] Xác định tỷ lệ read vs write traffic
- [ ] Quyết định số lượng replicas cần thiết
- [ ] Tính toán replication lag dự kiến
- [ ] Lên kế hoạch cho connection pooling
Triển khai:
- [ ] Primary đã cấu hình WAL streaming
- [ ] Replication user đã tạo với quyền phù hợp
- [ ] Ít nhất 2 replicas đang chạy và đồng bộ
- [ ] Application định tuyến reads đến replicas, writes đến primary
- [ ] Connection pooling đã cấu hình (PgBouncer khuyến nghị)
High Availability:
- [ ] Automatic failover đã cấu hình (Patroni + etcd)
- [ ] HAProxy hoặc tương tự cho virtual IP
- [ ] Đã kiểm tra failover thủ công ít nhất một lần
- [ ] Runbook failover đã được ghi lại
Giám sát:
- [ ] Giám sát replication lag (cảnh báo nếu > 2 giây)
- [ ] Kiểm tra sức khỏe replica (cảnh báo nếu replica xuống)
- [ ] Giám sát connection pool
- [ ] Giám sát hiệu suất query
- [ ] Cảnh báo dung lượng đĩa (WAL có thể làm đầy disk)
Kiểm tra:
- [ ] Đã load test với lưu lượng dự kiến
- [ ] Đã xác minh read-your-writes consistency
- [ ] Đã kiểm tra kịch bản primary failure
- [ ] Đã kiểm tra kịch bản replica failure
- [ ] Đã kiểm tra kịch bản network partition
#Kết Luận
Database replication là kỹ thuật scaling có ROI cao nhất mà bạn có thể triển khai:
Chỉ với vài ngày làm việc, bạn có thể:
- Tăng dung lượng đọc 5-10x
- Giảm độ trễ đọc 10-20x
- Cắt giảm chi phí database một nửa
- Đạt 99.95%+ uptime với automatic failover
Kết quả của chúng tôi sau khi triển khai replication:
- Thời gian phản hồi: 800ms → 45ms (nhanh hơn 17x)
- Throughput: 3,000 → 15,000 req/sec (tăng 5x)
- Chi phí: $1,200 → $600/tháng (tiết kiệm 50%)
- Uptime: 99.85% → 99.96% (giảm 3x sự cố)
Bắt đầu với 1 primary + 2 replicas.
Giám sát lag.
Thêm replicas khi cần.
Triển khai automatic failover với Patroni.
Bạn sẽ xử lý lưu lượng gấp 10x mà không phá vỡ ngân sách.